TIP
本文主要是介绍 Yarn-精华知识总结 。
# YARN
mapreduce程序应该是在很多机器上并行启动,而且先执行map task,当众多的maptask都处理完自己的数据后,还需要启动众多的reduce task,这个过程如果用用户自己手动调度不太现实,需要一个自动化的调度平台——hadoop中就为运行mapreduce之类的分布式运算程序开发了一个自动化调度平台——YARN
# 1.yarn的基本概念
yarn是一个分布式程序的运行调度平台
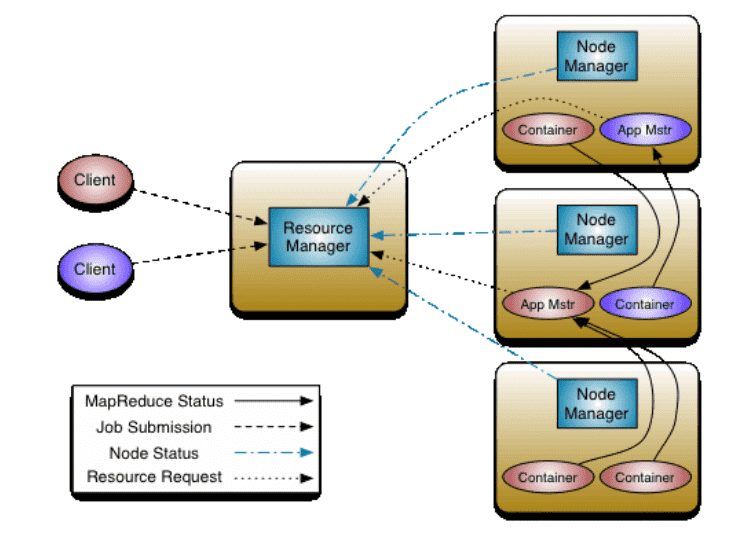
yarn中有两大核心角色:
# 1、Resource Manager
接受用户提交的分布式计算程序,并为其划分资源
管理、监控各个Node Manager上的资源情况,以便于均衡负载
ResourceManager(RM):
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
调度器 调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。需要注意的是,该调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的ApplicationMaster完成。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container,简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。此外,该调度器是一个可插拔的组件,用户可根据自己的需要设计新的调度器,YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler等。
应用程序管理器应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
ApplicationMaster(AM):用户提交的每个应用程序均包含一个AM,主要功能包括:
与RM调度器协商以获取资源(用Container表示);
将得到的任务进一步分配给内部的任务(资源的二次分配);
与NM通信以启动/停止任务;
监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
当前YARN自带了两个AM实现,一个是用于演示AM编写方法的实例程序distributedshell,它可以申请一定数目的Container以并行运行一个Shell命令或者Shell脚本;另一个是运行MapReduce应用程序的AM—MRAppMaster。
注:RM只负责监控AM,在AM运行失败时候启动它,RM并不负责AM内部任务的容错,这由AM来完成。
# 2、Node Manager
管理它所在机器的运算资源(cpu + 内存)
负责接受Resource Manager分配的任务,创建容器、回收资源
NodeManager(NM):NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
Container:Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
注:1. Container不同于MRv1中的slot,它是一个动态资源划分单位,是根据应用程序的需求动态生成的。
- 现在YARN仅支持CPU和内存两种资源,且使用了轻量级资源隔离机制Cgroups进行资源隔离。
YARN的资源管理和执行框架都是按主/从范例实现的——Slave ---节点管理器(NM)运行、监控每个节点,并向集群的Master---资源管理器(RM)报告资源的可用性状态,资源管理器最终为系统里所有应用分配资源。
特定应用的执行由ApplicationMaster控制,ApplicationMaster负责将一个应用分割成多个任务,并和资源管理器协调执行所需的资源,资源一旦分配好,ApplicationMaster就和节点管理器一起安排、执行、监控独立的应用任务。
需要说明的是, YARN不同服务组件的通信方式采用了事件驱动的异步并发机制,这样可以简化系统的设计。
https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html (opens new window)
# 2.YARN的资源管理
1、资源调度和隔离是yarn作为一个资源管理系统,最重要且最基础的两个功能。资源调度由resourcemanager完成,而资源隔离由各个nodemanager实现。
2、Resourcemanager将某个nodemanager上资源分配给任务(这就是所谓的“资源调度”)后,nodemanager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础和保证,这就是所谓的资源隔离。
3、当谈及到资源时,我们通常指内存、cpu、io三种资源。Hadoop yarn目前为止仅支持cpu和内存两种资源管理和调度。
4、内存资源多少决定任务的生死,如果内存不够,任务可能运行失败;相比之下,cpu资源则不同,它只会决定任务的快慢,不会对任务的生死产生影响。
# Yarn的内存管理:
yarn允许用户配置每个节点上可用的物理内存资源,注意,这里是“可用的”,因为一个节点上内存会被若干个服务贡享,比如一部分给了yarn,一部分给了hdfs,一部分给了hbase等,yarn配置的只是自己可用的,配置参数如下:
yarn.nodemanager.resource.memory-mb
表示该节点上yarn可以使用的物理内存总量,默认是8192m,注意,如果你的节点内存资源不够8g,则需要调减这个值,yarn不会智能的探测节点物理内存总量。
yarn.nodemanager.vmem-pmem-ratio
任务使用1m物理内存最多可以使用虚拟内存量,默认是2.1
yarn.nodemanager.pmem-check-enabled
是否启用一个线程检查每个任务证使用的物理内存量,如果任务超出了分配值,则直接将其kill,默认是true。
yarn.nodemanager.vmem-check-enabled
是否启用一个线程检查每个任务证使用的虚拟内存量,如果任务超出了分配值,则直接将其kill,默认是true。
yarn.scheduler.minimum-allocation-mb
单个任务可以使用最小物理内存量,默认1024m,如果一个任务申请物理内存量少于该值,则该对应值改为这个数。
yarn.scheduler.maximum-allocation-mb
单个任务可以申请的最多的内存量,默认8192m
# Yarn cpu管理:
目前cpu被划分为虚拟cpu,这里的虚拟cpu是yarn自己引入的概念,初衷是考虑到不同节点cpu性能可能不同,每个cpu具有计算能力也是不一样的,比如,某个物理cpu计算能力可能是另外一个物理cpu的2倍,这时候,你可以通过为第一个物理cpu多配置几个虚拟cpu弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟cpu个数。在yarn中,cpu相关配置参数如下:
yarn.nodemanager.resource.cpu-vcores
表示该节点上yarn可使用的虚拟cpu个数,默认是8个,注意,目前推荐将该值为与物理cpu核数相同。如果你的节点cpu合数不够8个,则需要调减小这个值,而yarn不会智能的探测节点物理cpu总数。
yarn.scheduler.minimum-allocation-vcores
单个任务可申请最小cpu个数,默认1,如果一个任务申请的cpu个数少于该数,则该对应值被修改为这个数
yarn.scheduler.maximum-allocation-vcores
单个任务可以申请最多虚拟cpu个数,默认是32.
# 3.安装yarn集群
yarn集群中有两个角色:
主节点:Resource Manager 1台
从节点:Node Manager N台
Node Manager在物理上应该跟data node部署在一起,为什么?
hdfs上的数据存储在datanode节点上,而nodemanager,要进行运算,就需要读取datanode上的数据块,如果部署在datanode节点上,可用直接本地读取,不需要再跨网络传输,速度更快,效率更高。
Resource Manager在物理上应该独立部署在一台专门的机器上(可用部署在任意的机器)
# 1 修改配置文件:
yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hdp-01</value>
</property>
# nodemanager给 mapreduce程序提供辅助功能,辅助shuffle
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name> yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name> yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
mapred-site.xml
添加mapreduce默认使用yarn来调度。
mapreduce.framework.name=yarn|local 默认是local
<property>
<name> mapreduce.framework.name</name>
<value>yarn</value>
</property>
# yarn集群配置参数说明:
yarn.nodemanager.resource.memory-mb 默认是8G
yarn.nodemanager.resource.cpu-vcores 默认是8
注意:如果内存不足2G,至少配置2G,即值为2048
如果内存配置低于2G,可能会导致mapreduce任务不能正常运行。
报错如下:
原因:
在mapred-default.xml中,有默认参数配置了(MR AppMaster)内存为1.5G。
每一个mapreduce 会启动一个MR AppMaster进行。
# 2、scp这个yarn-site.xml,mapred-site.xml到其他节点
cd /root/apps/Hadoop/etc/Hadoop/
for i in {2..4};do scp yarn-site.xml hdp-0$i:`pwd` ;done
for i in {2..4};do scp mapred-site.xml hdp-0$i:`pwd` ;done
yarn为每一个容器分配内存和核数:
yarn为每一个container分配的最小的内存:1024
yarn.scheduler.minimum-allocation-mb 1024
最大可分配的内存为8G:
yarn.scheduler.maximum-allocation-mb 8192
最小的cores: 1个 默认的就是一个
yarn.scheduler.minimum-allocation-vcores 1
最多可分配的cores:32个
yarn.scheduler.maximum-allocation-vcores 32
# 3、启动yarn集群:
主节点:# yarn-daemon.sh start resourcemanager
从节点:# yarn-daemon.sh start nodemanager
# 4、脚本批量启动:
在hdp-01上,修改hadoop的slaves文件,列入要启动nodemanager的机器
然后将hdp-01到所有机器的免密登陆配置好
启动yarn集群:(注:该命令应该在resourcemanager所在的机器上执行)
# start-yarn.sh
停止:# stop-yarn.sh
验证:用jps检查yarn的进程,用web浏览器查看yarn的web控制台
启动完成后,可以在windows上用浏览器访问resourcemanager的web端口:
[http://hdp-01:8088](http://hdp-01:8088/)
看resource mananger是否认出了所有的node manager节点
# 4.运行mapreduce程序
定义一个主类,用来描述job并提交job
提交job到yarn的客户端类(模板代码):
描述你的mapreduce程序运行时所需要的一些信息(比如用哪个mapper、reducer、map和reduce输出的kv类型、jar包所在路径、reduce task的数量、输入输出数据的路径)
/**
* 本类其实跟你的wordcount mapreduce程序关系不大
* 它只是用来描述你的mapreduce程序相关信息,并将mapreduce程序所在的jar包提交给yarn
*/
public class JobSubmitter {
public static void main(String[] args) throws Exception {
// 描述job信息
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "hdp-01");
Job job = Job.getInstance(conf);
// 指定mapreduce程序的jar包路径,通过类加载机制动态获取
job.setJarByClass(JobSubmitter.class);
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 指定map输出的keyvalue类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 指定最终输出的结果的keyvalue类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定job所要读取的数据源目录
FileInputFormat.setInputPaths(job, new Path("/wordcount/input"));
// 指定job输出结果的目录
FileOutputFormat.setOutputPath(job, new Path("/wordcount/output"));
// 指定reduce task的数量
job.setNumReduceTasks(1);
// 提交job给yarn
//job.submit();
boolean res = job.waitForCompletion(true);
System.exit(res?0:-1);
}
}
注意:FileInputFormat和FileOutputFormat导的包是:
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.io.Text;
- 将工程整体打成一个jar包并上传到linux机器上
这里打普通的jar包即可,不需要打成可执行的jar包。
准备好要处理的数据文件放到hdfs的指定目录中
用命令启动jar包中的Jobsubmitter,让它去提交jar包给yarn来运行其中的mapreduce程序 :
hadoop jar wc.jar cn.edu360.mr.wordcount.JobSubmitter .....
- 去hdfs的输出目录中查看结果
运行流程分析:
启动一个mapreduce任务的时候,通过jps可以看见:
提交任务的进程:
每一个mapreduce任务,都会有一个MRAppMaster的进程,该进程负责启动maptask和reducetask,
maptask和reducetask的进程名称叫做YarnChild
# 5.mapreduce任务运行方式总结:
# 5.1运行在yarn平台
# 5.1.1linux平台提交mapreduce任务到yarn上
所需参数:
Mapred-site.xml
mapreduce.framework.name yarn
core-site.xml
fs.defaultFS hdfs://hdp-01:9000
yarn-site.xml
yarn.resourcemanager.hostname hdp-01
# 5.1.2windows平台提交mapreduce任务到yarn
所需参数:
// 基本的参数配置
conf.set("fs.defaultFS", "hdfs://hdp-01:9000");
conf.set("yarn.resourcemanager.hostname","hdp-01");
conf.set("mapreduce.framework.name", "yarn");
// 配置跨平台执行的参数
conf.set("mapreduce.app-submission.cross-platform", "true");
// 伪装root用户
System.setProperty("HADOOP_USER_NAME", "root");
需要指定jar包路径:
// 需要设置jar包的路径
job.setJar("d:/wc.jar");
windows平台hadoop环境变量:
需要指定本地的hadoop的环境变量,(windows版本的hadoop安装包)
# 5.2本地运行(windows/linux)
可不配置任何参数,使用的是默认的参数
mapreduce.framework.name的默认值是local
windows本地运行
windows平台上执行本地的mapreduce任务,需要指定windows平台的输入输出路径:
// 设置输入路径 输出路径F
ileInputFormat.*setInputPaths*(job, new Path("f:/mrdata/wordcount/input/"));
FileOutputFormat.*setOutputPath*(job, new Path("f:/mrdata/wordcount/output/"));
# 参考文章
- https://www.cnblogs.com/lq0310/p/9839178.html










