Spark-应用案例介绍
更新时间
浏览
TIP
本文主要是介绍 Spark-应用案例介绍 。
# Spark基本介绍(阿里云和相关案例))
# 概述
RDS、NoSQL相关的数据库服务擅长在线存储查询场景,X-Pack Spark服务通过外部计算资源的方式,为Redis、Cassandra、MongoDB、HBase、RDS存储服务提供复杂分析、流式处理及入库、机器学习的能力,从而更好的解决用户数据处理相关场景问题。
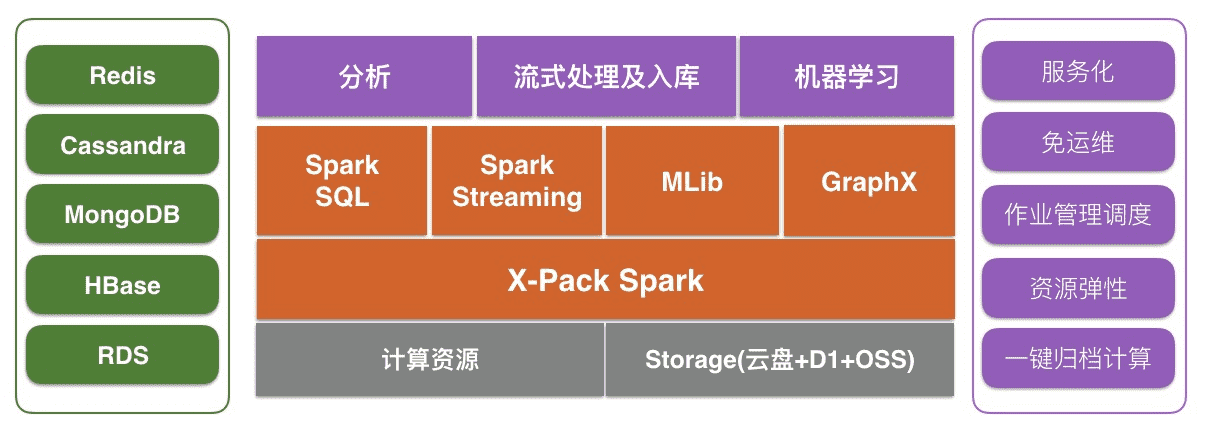
X-Pack Spark服务具有以下几个特点:
- 数据工作台:支持交互式、作业管理、工作流、资源管理、元数据管理,从测试、开发、上线一站式开发体验
- Spark多源connector:一键关联cassandra、hbase、mongo、redis、rds等集群,免去调试的烦恼,更加便捷的分析其他数据库的数据
- 可维护性:支持小版本升级、监控、报警,免去Spark集群维护
- 离线数仓能力:支持一键归档在线库rds、polardb、mongo、cassandra、hbase数据到Spark,构建统一的数仓;支持HiveMeta管理数仓数据;
- 成本:X-Pack Storage支持基于云盘、D1的HDFS、以及OSS,分级存储满足不同容量、成本场景需求;计算节点支持弹性伸缩,最低化成本消耗
ApsaraDB 在线数据库擅长在线查询场景,X-Pack Spark为在线数据库用户提供混合负载的能力,主要包括:
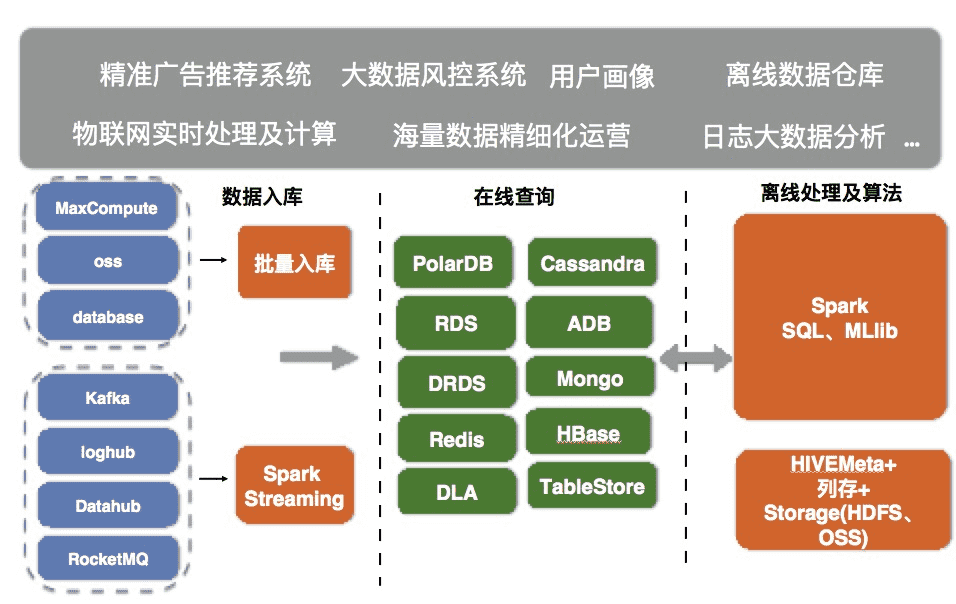
- 流式处理及入库:Spark Streaming为数据库提供流式ETL入库(延迟s级别);
- 生态打通:Spark的多数据源能力,提供外部数据源批量入库、联邦分析能力;
- 复杂计算及算法:支持SQL、python、java、scala、R多语言,支持复杂的数据过程处理(类似PL/SQL)、机器学习等;
- 离线数仓(复杂分析):一键归档数据到Spark,为数据库添加PB级别离线数仓能力,支持复杂分析,提供天/月级别的报表等;
- 非结构化处理:搭配HDFS/OSS存储为数据库添加非结构化数据存储处理能管理(CSV、XML、Parquet多种存储)。
# 典型场景
# 1、统一数据ETL服务
- 场景:在业务的选型和发展中,不同类型的数据会存储在不同的数据库中,数据孤岛对于企业发展不利,统一的数据ETL服务能够让数据之间产生连接交互,产生更多的价值。
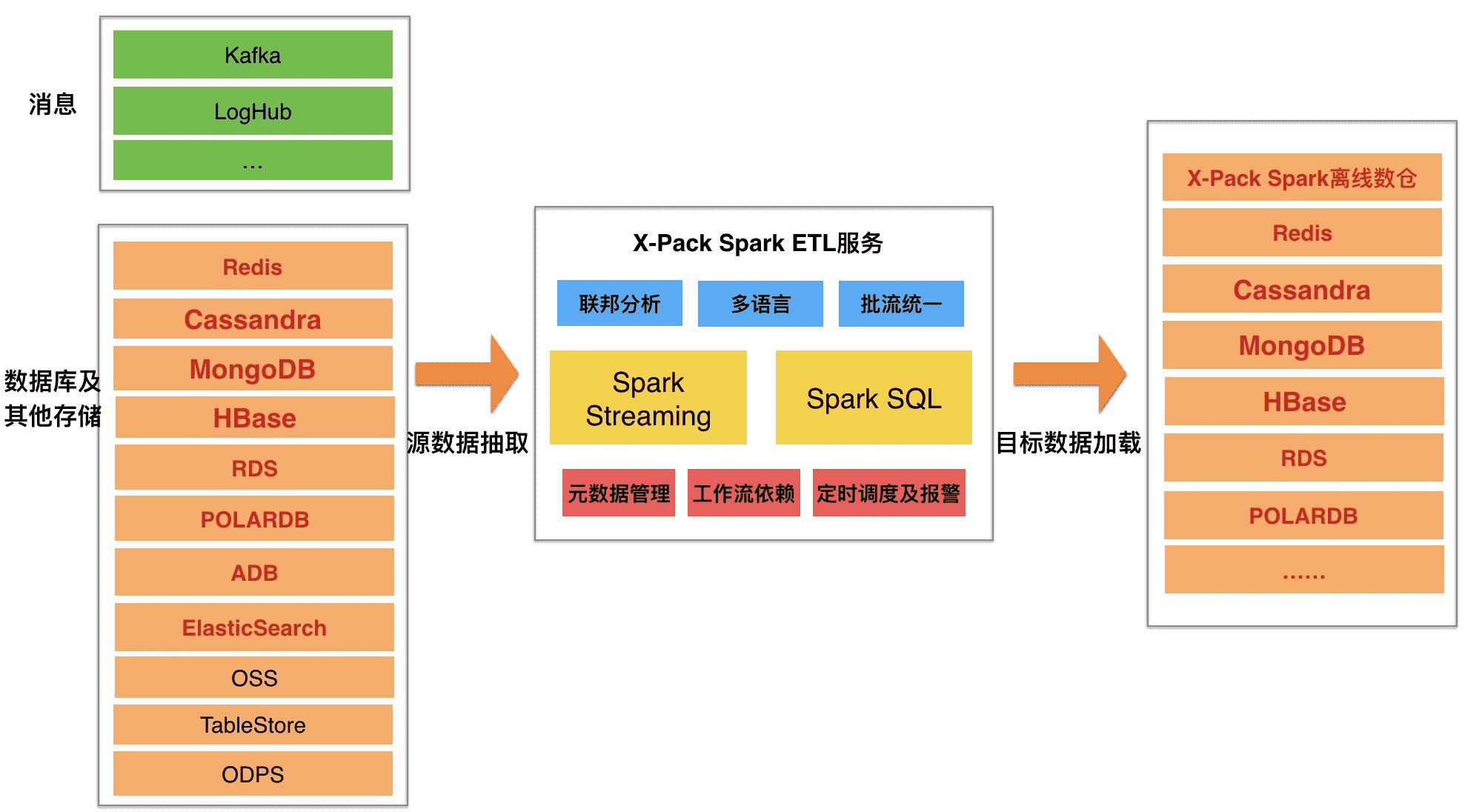
价值及优势:
- 丰富数据源:支持阿里云包括数据库、消息中间件、oss基本所有数据源
- ETL能力:支持批流统一、多源联邦ETL、支持SQL&Python&scala等语言
- 数据管理能力:支持元数据管理、工作流依赖、作业定时调度、报警等
# 2、 大数据用户画像及推荐场景
- 场景:随着积累的用户越来越多,推出商品推荐功能,需要实时对用户行为日志进行ETL分析、存储以及模型计算等。

价值及优势:
- spark多源处理能力可以对接基本所有的数据系统,比如RDS、Cassandra、MongoDB、HBase、Redis,以及kafka、loghub等
- spark 流、批、机器学习统一的能力,可以一站式解决计算问题
- Cassandra/HBase适合作为用户画像的统一宽表存储
- mongoDB作为商品信息的存储,Redis作为推荐结果的加速层
# 3、 物联网日志处理平台
- 场景:对于车联网、物联网、游戏行业,会有百万终端百TB级数据不间断写入,数十亿级数据量下在线查询,以及对冷数据的大数据计算挖掘的需求
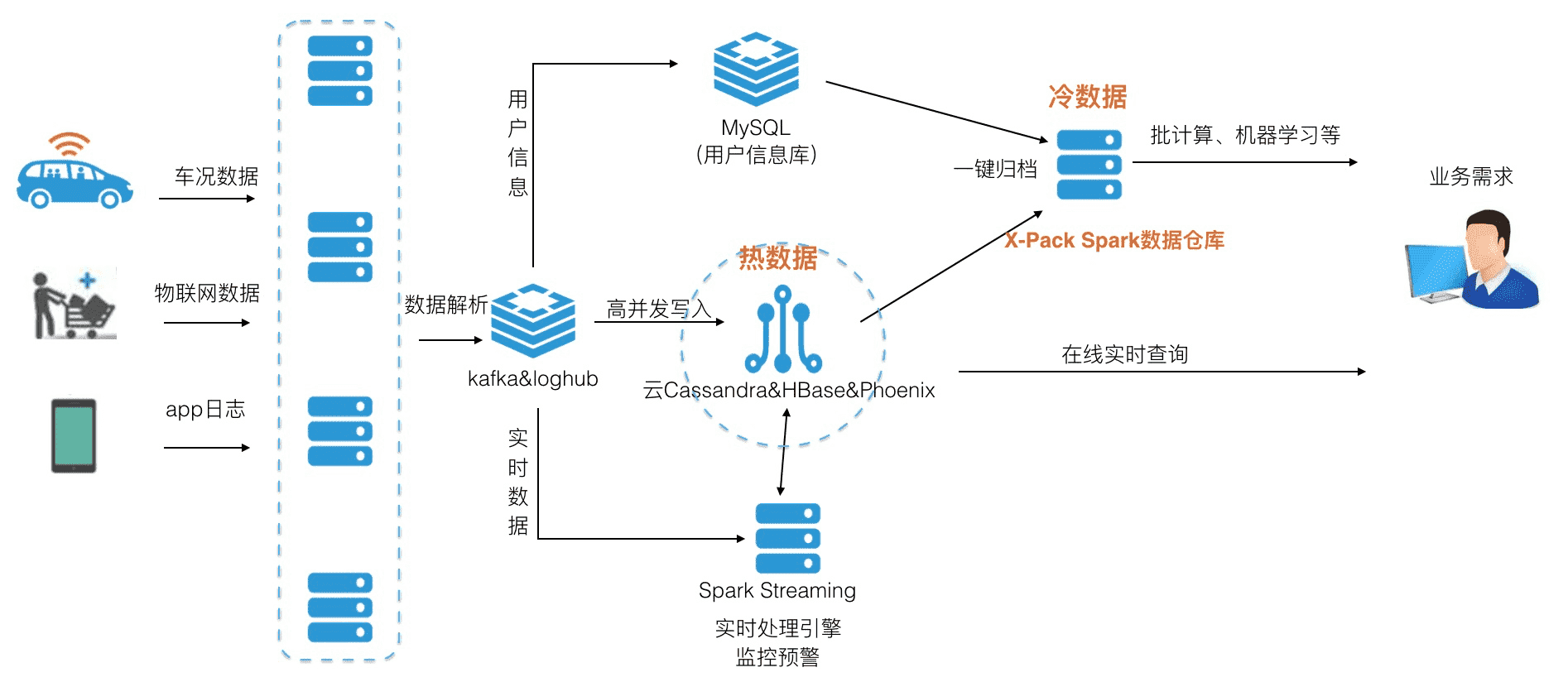
价值及优势:
- 冷热分离存储降成本:比如3个月的热数据存储在云Cassandra&hbase*phoenix这样的大数据在线存储库(基于SSD盘),全量的冷数据存储在X-Pack Spark数据仓库(HiveMeta)(基于本地盘D1机型,以及oss存储);
- 存储及计算一体化:写入云Cassandra&hbase*phoenix&mysql在线库的数据,通过log实时归档 (opens new window)到X-Pack Spark数据仓库(HiveMeta)来做大数据的计算分析;
# 4、 大数据风控系统
- 场景:在电商、游戏、广告、金融等行业都需要记录用户的行为日志以及订单明细,做风控处理,风控处理会包括事前风控、事中风控、事后风控,这样一套具有存储、计算、机器学习能力的平台
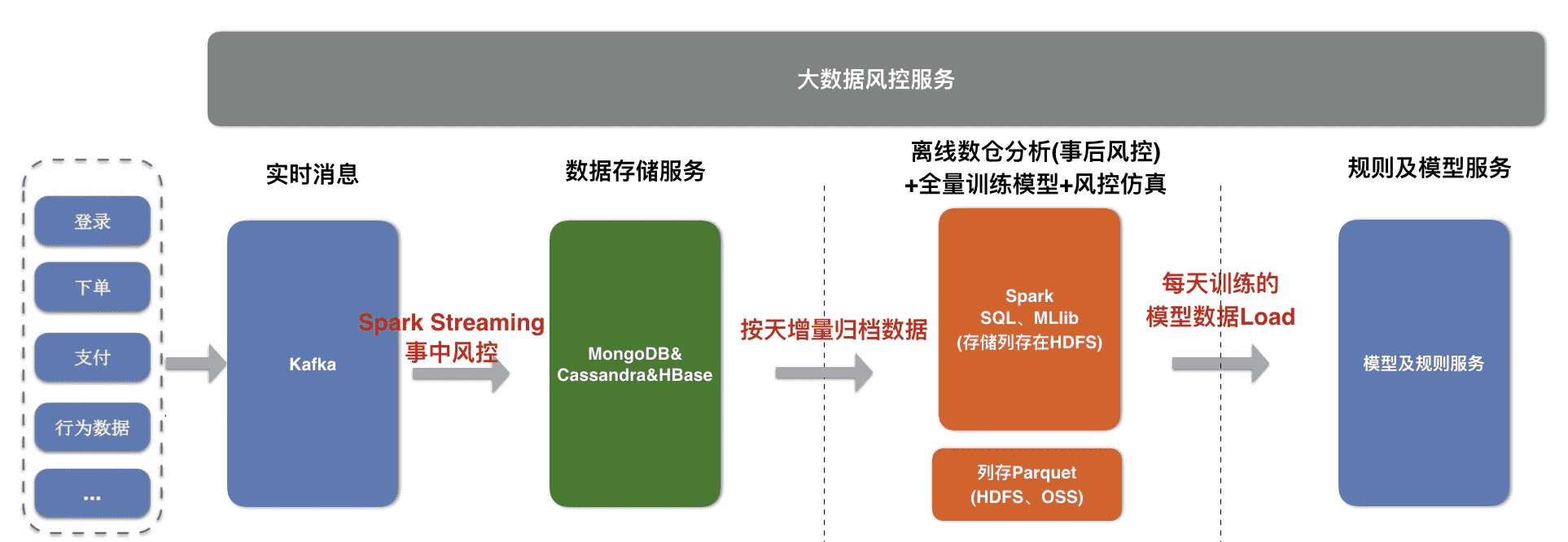
价值及优势:
- 存储、计算、机器学习一体化:在线存储针对不同的数据类型可以选择MongoDB&Cassandra&HBase,比如mongoDB适合存储json、Cassandra适合实时在线使用SQL存储宽表、HBase适合做KV在线存储;而Spark作为业界最成熟的大数据统一平台支持流、批计算、机器学习能力
- 事前、事中、事后风控同时支持:基于在线存储的风控结果可以做事前风控、利用spark streaming可以做事中风控、x-pack spark的数据仓库能力可以用来做全量数据的时候风控
- 模型训练及仿真一体化:spark mllib及计算能力可用来做模型的训练,同时x-pack spark的离线数仓能力可以用来对规则及模型做仿真评测
# 5、数据中台构建
- 场景:企业前期在快速支持业务时,数据会存储在不同的系统中,比如Cassandra、MongoDB、HBase、RDS、polardb、kafka、loghub、tablestore、adb等中,之后会有构建统一的数据仓库的需求。X-Pack Spark的数仓Storage、及多源connector的能力很适合。
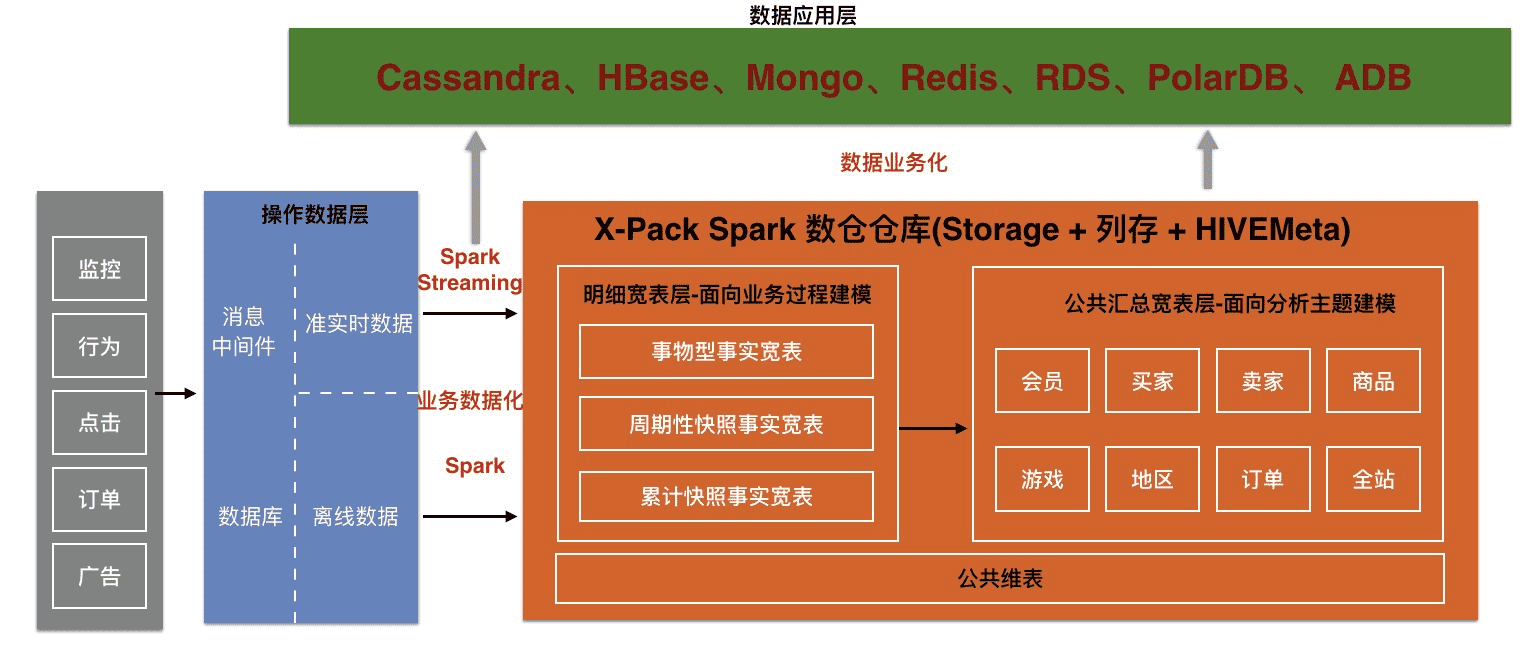
价值及优势:
- X-Pack Spark多数据源:X-Pack Spark支持对接基本全部的消息中间件、NoSQL、OLTP、OLAP等数据系统
- 异构数据源归档能力:支持对Cassandra、MongoDB、HBase、RDS等数据源进行一键归档
- X-Pack Spark数据仓库能力:X-Pack Spark内置HiveMeta用来管理大量复杂的数仓表
- X-Pack Spark Storage能力:支持高效盘HDFS、本地盘HDFS、OSS存储不同成本的存储介质
- X-Pack Spark Storage资源弹性:支持计算资源根据计算复杂弹性伸缩
- X-Pack Spark开发者能力:支持SQL、Python、scala、java等语言进行分析计算开发
# 参考文章
- https://help.aliyun.com/document_detail/93899.html










