TIP
本文主要是介绍 大数据-技术基础知识 。
# 通俗介绍大数据技术
如今,大家都在说大数据,比如AI算法、智慧城市、精准营销、推荐系统...
但其实,大家可能仅仅是对“大数据”这三个词比较熟悉,至于大数据究竟是个啥,底层的技术结构、技术概念是什么,则完全不懂。
这篇文章,就希望通过通俗易懂的语言,为大家介绍下大数据的基本概念。
# 大数据的定义:
麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
大数据最大的特征,自然就是数据量巨大,大到传统的数据处理软件如Excel、Mysql等都无法很好的支持分析。这也意味着大数据阶段,无论是数据的存储还是加工计算等等过程,用到的处理技术也会完全不同,例如Hadoop、Spark等等。
# 大数据的架构:
在企业内部,数据从生产、存储,到分析、应用,会经历各个处理流程。它们相互关联,形成了整体的大数据架构。
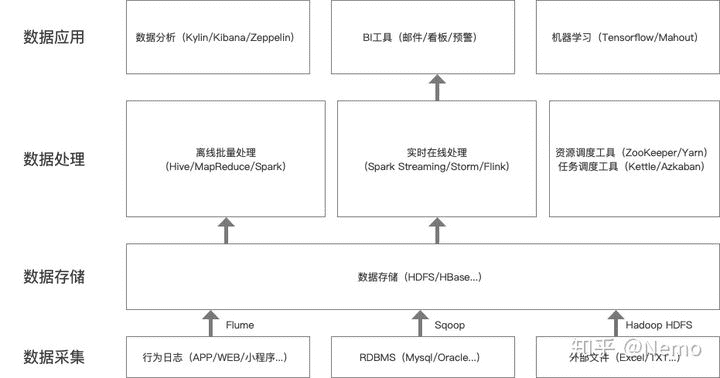
通常来说,在我们最终查看数据报表,或者使用数据进行算法预测之前,数据都会经历以下这么几个处理环节:
- 数据采集:是指将应用程序产生的数据和日志等同步到大数据系统中。
- 数据存储:海量的数据,需要存储在系统中,方便下次使用时进行查询。
- 数据处理:原始数据需要经过层层过滤、拼接、转换才能最终应用,数据处理就是这些过程的统称。一般来说,有两种类型的数据处理,一种是离线的批量处理,另一种是实时在线分析。
- 数据应用:经过处理的数据可以对外提供服务,比如生成可视化的报表、作为互动式分析的素材、提供给推荐系统训练模型等等。
我们现在常用的大数据技术,其实都是基于Hadoop生态的。Hadoop是一个分布式系统基础架构,换言之,它的数据存储和加工过程都是分布式的,由多个机器共同完成。通过这样的并行处理,提高安全性和数据处理规模。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。我们可以把HDFS(Hadoop Distributed File System)理解为一套分布式的文件系统,大数据架构里的海量数据就是存储在这些文件里,我们每次分析,也都是从这些文件里取数。
而MapReduce则是一种分布式计算过程,它包括Map(映射)和Reduce(归约)。当你向MapReduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,每一个Map任务处理输入数据中的一部分,当Map任务完成后,Reduce会把前面若干个Map的输出汇总到一起并输出。相当于利用了分布式的机器,完成了大规模的计算任务。
理解了大数据技术的基础——Hadoop,我们再来看看每个数据环节具体的技术。
# 数据采集:
数据并不是天然就从Hadoop里生长出来,它往往存在于业务系统、外部文件里。当我们需要收集这些不同场景下的数据时,就需要用到各种不同的数据采集技术。这其中包括用于数据库同步的Sqoop,用于采集业务日志的Flume,还有用于数据传输的Kafka等等。
- 数据迁移:Sqoop是一个在结构化数据和Hadoop之间进行批量数据迁移的工具,结构化数据可以是MySQL、Oracle等RDBMS。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。
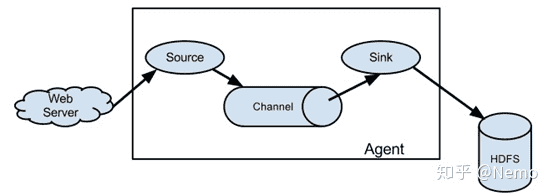
- 日志采集:Flume是一个分布式的海量日志采集系统。支持在日志系统中定制各类数据发送方,并写到各种数据接受方的能力。它的基本结构如下,包含三个部分:数据收集组件Source,缓存Channel,保存Sink。多个Agent也可以组合使用。
- 数据传输:Kafka是一个著名的分布式消息队列。通过它,数据的发送方和接收方可以准确、稳定的传输数据。它以可水平扩展,并支持高吞吐率。kafka的结构如下图所示:
# 数据存储:
采集下来的数据需要保存到Hadoop里,从物理的角度看,它们保存为一个一个的HDFS文件。当然,除了HDFS以外,Hadoop还提供了一些配套工具,如便于实时处理数据的列族数据库Hbase,以及一个类似SQL的查询工具Hive,方便对HDFS数据进行查询。
- HDFS:在Hadoop里,底层的数据文件都存储在HDFS里,它是大数据的底层基础。HDFS容错率很高,即便是在系统崩溃的情况下,也能够在节点之间快速传输数据。
- Hbase:是一个高可靠性、高性能、面向列、可伸缩的分布式列族数据库,可以对大数据进行随机性的实时读取/写入访问。基于HDFS而建。
- Hive:是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。Hive通过元数据来描述Hdfs上的结构化文本数据,通俗点来说,就是定义一张表来描述HDFS上的结构化文本,包括各列数据名称,数据类型是什么等,方便我们处理数据,当前很多SQL ON Hadoop的计算引擎均用的是hive的元数据,如Spark SQL、Impala等。
# 数据处理:
数据处理:
批数据处理:批处理是指一次批量的数据处理,它存在明确的开始和结束节点。常见的技术包括Hadoop自带的MapReduce,以及Spark。
- MapReduce:如前文所说,通过Hadoop的MapReduce功能,可以将大的数据处理任务,拆分为分布式的计算任务,交给大量的机器处理,最终等处理完后拼接成我们需要的结果。这是一张批量处理的逻辑。
- Spark:Spark是一个高速、通用大数据计算处理引擎。拥有Hadoop MapReduce所具有的优点,但不同的是Job的中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
流数据处理:对于一些需要实时不间断处理的数据而言,等待MapReduce一次次缓慢加工,将文件反复保存到HDFS里并读取,显然太费时间了。一些新的流式数据处理工具被研发出来,它们的处理流程和批处理完全不同:
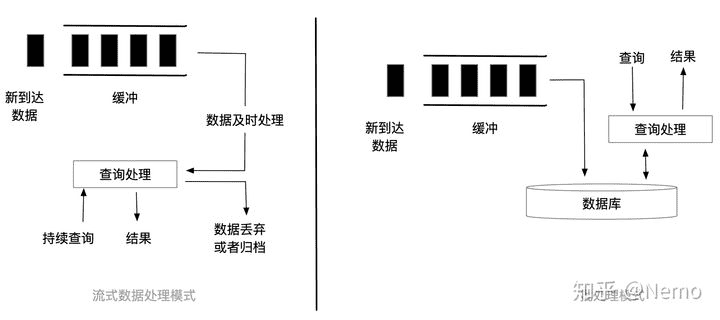
- Spark Streaming:基于 Spark,另辟蹊径提出了 D-Stream(Discretized Streams)方案:将流数据切成很小的批(micro-batch),用一系列的短暂、无状态、确定性的批处理实现流处理。
- Storm:是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop。
- Flink:可以理解为Storm的下一代解决方案,与HDFS完全兼容。Flink提供了基于Java和Scala的API,是一个高效、分布式的通用大数据分析引擎。更主要的是,Flink支持增量迭代计算,使得系统可以快速地处理数据密集型、迭代的任务。
资源管理:
在完成大数据处理任务的过程中,难免会涉及到多个任务、服务之间协调。这里面既包括资源的协调,也包括任务的协调。
- ZooKeeper:是一个分布式的,开放源码的分布式应用程序协调服务。假设我们的程序是分布式部署在多台机器上,如果我们要改变程序的配置文件,需要逐台机器去修改,非常麻烦,现在把这些配置全部放到zookeeper上去,保存在 zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 zookeeper 的通知,然后从 zookeeper 获取新的配置信息应用到系统中,以此保证各个程序的配置信息同步。
- Yarn:是一个分布式资源调度器组件。这个组件的主要作用是在每次接收到请求后,会查看当下的各个子节点的状况,统筹出运算资源的调度方案来保证任务可以顺利执行。通常来说,Yarn所调度的资源常常包括磁盘空间的资源,内存的资源和通讯带宽的资源等。
ETL任务管理:
- Kettle:这是一个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的界面来描述任务过程和彼此的依赖关系,以此来设定任务流程。
- Azkaban:是一款基于Java编写的任务调度系统任务调度,来自LinkedIn公司,用于管理他们的Hadoop批处理工作流。Azkaban根据工作的依赖性进行排序,提供友好的Web用户界面来维护和跟踪用户的工作流程。
# 数据应用:
# 分析工具:
数据处理完后,最终要想发挥价值,很重要的环节是进行分析和展示。很多工具都能提供分析支持,例如Kylin和Zeppelin。
- Kylin:是一个开源的分布式分析引擎,提供了基于Hadoop的超大型数据集(TB/PB级别)的SQL接口以及多维度的OLAP分布式联机分析。通过预先定义cube的方式,使得它能在亚秒内查询巨大的Hive表。
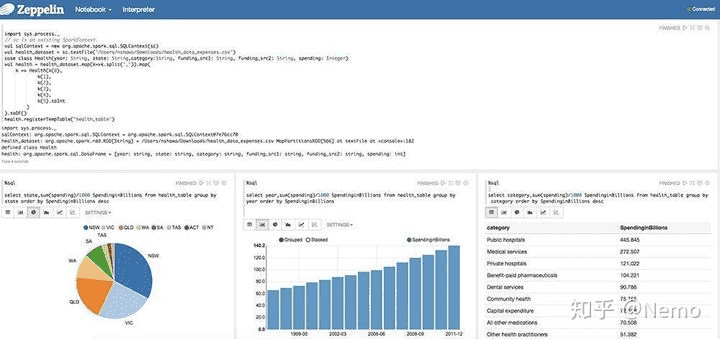
- Zeppelin:是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等。
# 机器学习:
除了分析外,大数据很重要的一个应用场景就是AI,借助于一些机器学习工具,大数据可以灵活的完成AI相关工作。
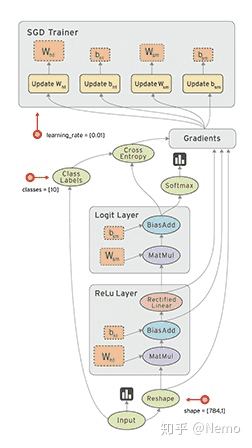
- Tensorflow:是Google开源的一款深度学习工具,它是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。在这个图中,节点(Nodes)表示数学操作,线(edges)表示在节点间相互联系的多维数据数组,即张量(tensor)。它配备了大量的机器学习相关API,能大幅提升机器学习的工作效率。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
- Mahout:是一个算法库,集成了很多算法。旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包括许多实现,包括聚类、分类、推荐引擎、频繁子项挖掘等等。
# 相关概念英文缩写
数据采集:data collection 缩写:dc
数据存储:data storage 缩写:ds
数据处理(数据加工):data processing 缩写:dp
数据仓库: data warehouse 缩写:dw
数据挖掘:data mining 缩写:dm
# 参考文章
- https://zhuanlan.zhihu.com/p/160903909










