TIP
本文主要是介绍 Tez-精华知识总结 。
# HIVE执行引擎TEZ学习以及实际使用
# 概述
Tez是Apache最新的支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。Tez并不直接面向最终用户——事实上它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。Hadoop传统上是一个大量数据批处理平台。但是,有很多用例需要近乎实时的查询处理性能。还有一些工作则不太适合MapReduce,例如机器学习。Tez的目的就是帮助Hadoop处理这些用例场景。
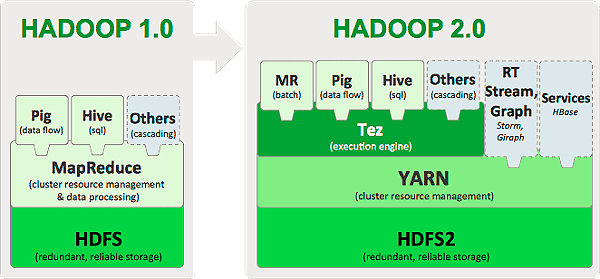
Tez构建在YARN之上,后者是Hadoop所使用的新资源管理框架。Tez产生的主要原因是绕开MapReduce所施加的限制。除了必须要编写Mapper和Reducer的限制之外,强制让所有类型的计算都满足这一范例还有效率低下的问题——例如使用HDFS存储多个MR作业之间的临时数据,这是一个负载。在Hive中,查询需要对不相关的key进行多次shuffle操作的场景非常普遍,例如join - grp by - window function - order by。
# Tez产生背景
MR性能差,资源消耗大,如:Hive作业之间的数据不是直接流动的,而是借助HDFS作为共享数据存储系统,即一个作业将处理好的数据写入HDFS,下一个作业再从HDFS重新读取数据进行处理。很明显更高效的方式是,第一个作业直接将数据传递给下游作业。
MR 默认了map和reduce阶段,map会对中间结果进行分区、排序,reduce会进行合并排序,这一过程并不适用于所有场景。
引擎级别的Runtime优化:MR执行计划在编译时已经确定,无法动态调整(?)。然而在执行ETL和Ad-hoc等任务时,根据实际处理的表大小,动态调整join策略、任务并行度将大大缩短任务执行时间。
下面给您展示一张Tez官方图,您就可以简单明白Tez和MapReduce的关系。
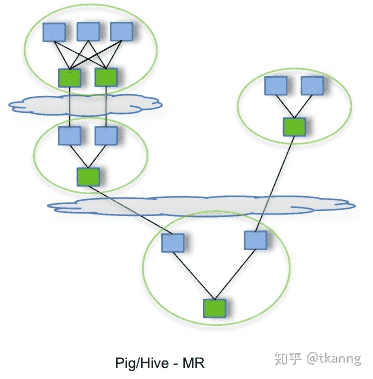
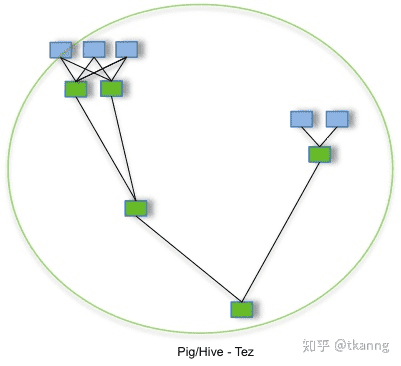
总的来说之前mapReduce在map和reduce阶段都会产生I/O落盘,但是Tez就不要这一步骤了。
目前hive使用了Tez(Hive是一个将用户的SQL请求翻译为MR任务,最终查询HDFS的工具Tez采用了DAG(有向无环图)来组织MR任务。
核心思想:将Map任务和Reduce任务进一步拆分,Map任务拆分为Input-Processor-Sort-Merge-Output,Reduce任务拆分为Input-Shuffer-Sort-Merge-Process-output,Tez将若干小任务灵活重组,形成一个大的DAG作业。
Tez与oozie不同:oozie只能以MR任务为整体来管理、组织,本质上仍然是多个MR任务的执行,不能解决上面提到的多个任务之间硬盘IO冗余的问题。
Tez只是一个Client,部署很方便。 目前Hive使用了Tez(Hive是一个将用户的SQL请求翻译为MR任务,最终查询HDFS的工具)。
# Tez原理
Tez包含的组件:
有向无环图(DAG)——定义整体任务。一个DAG对象对应一个任务。
节点(Vertex)——定义用户逻辑以及执行用户逻辑所需的资源和环境。一个节点对应任务中的一个步骤。
边(Edge)——定义生产者和消费者节点之间的连接。
边需要分配属性,对Tez而言这些属性是必须的,有了它们才能在运行时将逻辑图展开为能够在集群上并行执行的物理任务集合。下面是一些这样的属性:
数据移动属性,定义了数据如何从一个生产者移动到一个消费者。
调度(Scheduling)属性(顺序或者并行),帮助我们定义生产者和消费者任务之间应该在什么时候进行调度。
数据源属性(持久的,可靠的或者暂时的),定义任务输出内容的生命周期或者持久性,让我们能够决定何时终止。
该模型所有的输入和输出都是可插拔的。为了方便,Tez使用了一个基于事件的模型,目的是为了让任务和系统之间、组件和组件之间能够通信。事件用于将信息(例如任务失败信息)传递给所需的组件,将输出的数据流(例如生成的数据位置信息)传送给输入,以及在运行时对DAG执行计划做出改变等。Tez还提供了各种开箱即用的输入和输出处理器。这些富有表现力的API能够让更高级语言(例如Hive)的编写者很优雅地将自己的查询转换成Tez任务。
TEZ技术:
Application Master Pool 初始化AM池。Tez先将作业提交到AMPoolServer服务上。AMPoolServer服务启动时就申请多个AM,Tez提交作业会优先使用缓冲池资源
Container Pool AM启动时会预先申请多个Container
Container重用
TEZ实现方法:
Tez对外提供了6种可编程组件,分别是:
Input:对输入数据源的抽象,它解析输入数据格式,并吐出一个个Key/value
Output:对输出数据源的抽象,它将用户程序产生的Key/value写入文件系统
Paritioner:对数据进行分片,类似于MR中的Partitioner
Processor:对计算的抽象,它从一个Input中获取数据,经处理后,通过Output输出
Task:对任务的抽象,每个Task由一个Input、Ouput和Processor组成
Maser :管理各个Task的依赖关系,并按顺依赖关系执行他们
除了以上6种组件,Tez还提供了两种算子,分别是Sort(排序)和Shuffle(混洗),为了用户使用方便,它还提供了多种Input、Output、Task和Sort的实现
# DAG
Edge:定义了上下游Vertex之间的连接方式。
Edge相关属性:
- Data movement:定义了producer与consumer之间数据流动的方式。
- One-To-One: 第i个producer产生的数据,发送给第i个consumer。这种上下游关系属于Spark的窄依赖。
- Broadcast: producer产生的数据路由都下游所有consumer。这种上下游关系也属于Spark的窄依赖。
- Scatter-Gather: producer将产生的数据分块,将第i块数据发送到第i个consumer。这种上下游关系属于Spark的宽依赖。
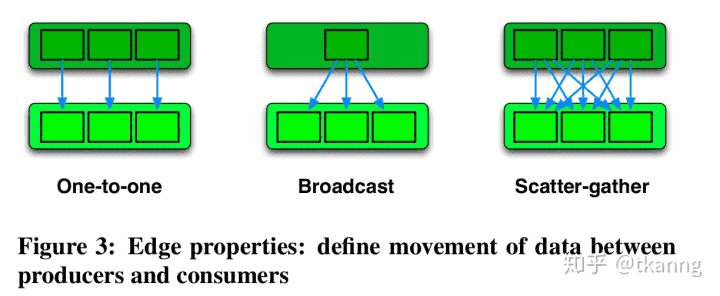
Scheduling:定义了何时启动consumer Task
Sequential: Consumer task 需要producer task结束后启动,如:MR。
Concurrent: Consumer task 与producer task一起启动,如:流计算。
Data source:定义了任务outp的生命周期与可靠性。
Persisted: 当任务退出后,该任务output依然存在,但经过一段时间后,可能会被删除,如:Mapper输出的中间结果。
Persisted-Reliable: 任务output总是存在,比如,MR中reducer的输出结果,存在HDFS上。
Ephemeral: 任务输出只有当该task在运行的时候,才存在,如:流计算的中间结果。
举例——MapReduce在Tez的编程模型
一个DAG图中只有两个Vertex,Map Vertex与Reduce Vertex。
连接Map Vertex与Reduce Vertex的Edge有以下属性:
- Data movement:
- Scatter-Gather Scheduling:
- Sequential Data Source:
- Map Vertex的Data Source为Persisted-Reliable,
- reduce Vertex 的Data Source为Persisted
Tez Api实现WordCount

# Runtime API——Input/Processor/Output
Task是Tez的最小执行单元,Vertex中task的数量与该vertex的并行度一致。以下是Input、Processor、Output均需要实现的接口:
List<Event> initialize(Tez*Context) -This is where I/P/O receive their corresponding context objects. They can, optionally, return a list of events.
handleEvents(List<Event> events) – Any events generated for the specific I/P/O will be passed in via this interface. Inputs receive DataMovementEvent(s) generated by corresponding Outputs on this interface – and will need to interpret them to retrieve data. At the moment, this can be ignored for Outputs and Processors.
List<Event> close() – Any cleanup or final commits will typically be implemented in the close method. This is generally a good place for Outputs to generate DataMovementEvent(s). More on these events later.
Input: 接收上游Output事件,获取上游数据位置;从physical Edge中获取实际数据;解析实际数据,为Processor提供统一的逻辑试图;
Processor: 利用Input获取实际数据,执行用户逻辑,最后输出;
Output: 将Processor提供的数据,进行分区;向下游Input发送事件;
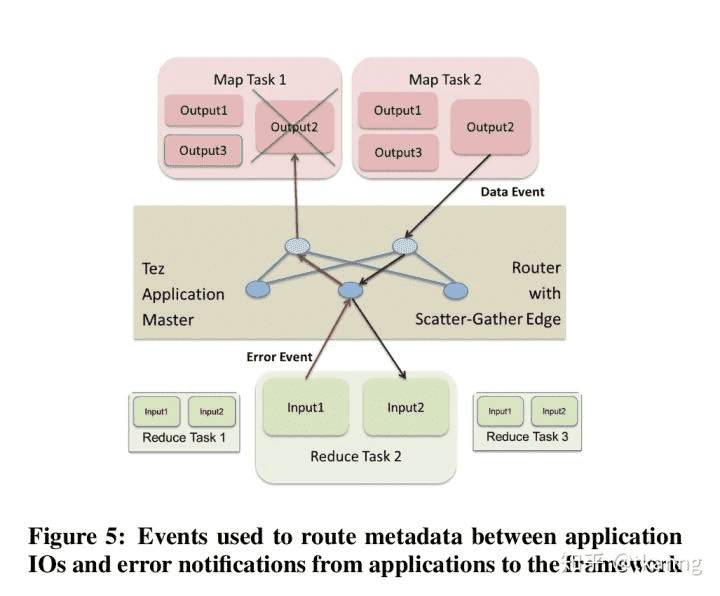
Tez的事件驱动机制: Tez中各个组件通过不同类型的Event进行通信。
数据传输:Output通过ShuffleEvent传递上游数据位置,AM负责将Event路由到相应Input中。
容错:Input当无法获取到上游数据时,会通知框架重新调度上游任务,这也意味着任务成功完成后,仍然会被重新调度。
runtime执行计划优化:根据上游Map Stage产生的数据大小,动态reducer并行度。Output产生的事件路由到可拔插的Vertex/Edge management module,对应moudule就可以对runtime执行计划进行调整。
# Runtime优化
任务运行时,程序知晓更多任务相关的信息,通过这些信息,我们可以动态修改修改执行计划,比如:修改mapper或reducer数量,决定何时启动reducer等。在Tez中,不同组件通过不同事件类型,进行通信。
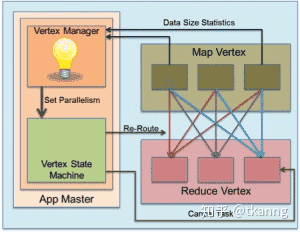
动态修改reducer并行度:MapTask通过VertexManager类型的事件向ShuffleVertextManager发送信息,比如:所处理的partition大小等。 ShuffleVertexManager通过所获得的信息,可以估算出所有Task的输出数据大小,最后来调整下游reduce Vertex的并行度,如下图:
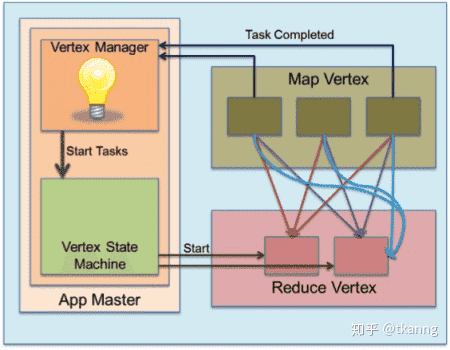
reducer"慢"启动(预先启动): 上游MapTask通过事件不断向ShuffleVertexManager汇报任务完成情况,ShuffleVertexManager通过这些信息,可以判断何时启动下游reduceTask与需要启动的reduceTask数量。
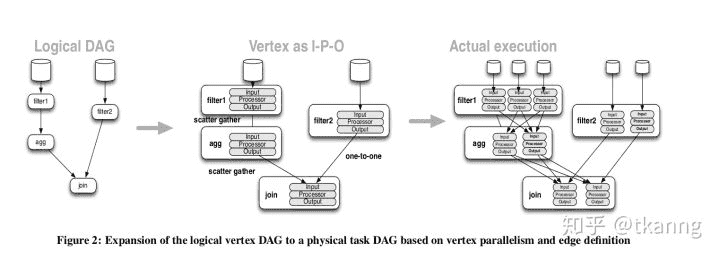
# 从逻辑执行计划到物理执行计划
从逻辑DAG到最后物理执行计划示意图:
# 其他优化措施
Tez Session: 与数据库session相似,在同一个Tez Session中,可串行执行多个Tez Dag。Tez Session避免了AM的多次启动与销毁,在有多个DAG图的Tez作业(HQL任务)中大大减小了任务执行时间。
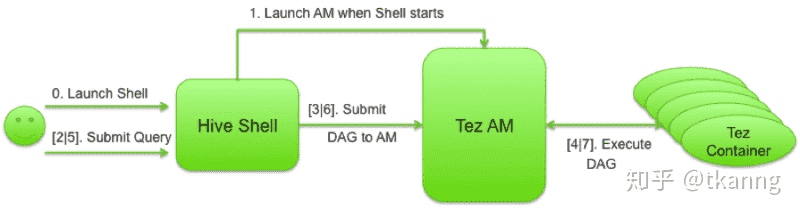
这也是为什么在Tez-UI中,一个HQL任务,只有一个Application,却有多个DAG(MR中一个HQL任务,有多个Application)。
Tez相关参数:


Container复用
问题:
container的资源兼容? 被先后调度到同一个container的多个task所需要的资源,必须与container的资源相互兼容。也就是说,container拥有的资源,如:jar包,Memory,CPU等,需要是task所需资源的“超集”。
怎么调度? 进行container复用时,Tez对Task进行调度。Tez会依据:任务本地性、任务所需资源、pending任务的优先级等因素,进行任务调度。
优点:
减少作业执行过程中JVM的创建与销毁带来的开销
减小对RM的请求压力
运行在同一container上task之间的数据共享。比如,MapJoin中可以通过共享小表数据的方式,减少资源消耗。
相关参数:
# Tez优缺点
优点:
避免中间数据写回HDFS,减小任务执行时间
vertex management模块使runtime动态修改执行计划变成可能
input/processor/output编程模型,大大提高了任务模型的灵活性
提供container复用机制与Tez Session,减少资源消耗
缺点:
出现数据重复问题等数据质量问题
Tez与Hive捆绑,在其他领域应用较少
社区不活跃
# Tez安装过程
1.下载tez src解压,修改pom.xml, 将hadoop.version改为2.7.2,最好用非root用户编译
mvn clean package -DskipTests=true -Dmaven.javadoc.skip=true
Github-refer:https://github.com/apache/tez
Download-refer:http://tez.apache.org/
2.编译成功后,在tez-dist/target目录下,能够发现如下文件
archive-tmp maven-archiver tez-0.8.4 tez-0.8.4-minimal tez-0.8.4-minimal.tar.gz tez-0.8.4.tar.gz tez-dist-0.8.4-tests.jar
3.将tez-0.8.4-minimal上传到hdfs上,本例中上传到/tez目录下 Hadoop fs –put tez-0.8.4-minimal.tar.gz /tez/
4, 将tez-0.8.4-minimal.tar.gz考到/usr/hive下,并解压到./tez下
taz –zxvf tez-0.8.4-minimal.tar.gz –C ./tez
拷贝tez的lib下或者主目录下jar包===》到hive主目录下lib中去
5.在客户端安装tez-0.8.4-minimal,并且在conf目录下建立tez-site.xml并正确配置
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/user/tez/tez-0.8.5-minimal.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
6.在hive的客户端配置环境变量 (可以配置到/etc/profile.d/Hadoop.sh
export TEZ_HOME=/usr/hive/tez
for jar in `ls ${TEZ_HOME}|grep jar`;do
export HADOOP_CLASSPATH=${TEZ_HOME}/$jar:${HADOOP_CLASSPATH}
done
for jar in `ls ${TEZ_HOME}/lib/|grep jar`;do
export HADOOP_CLASSPATH=${TEZ_HOME}/lib/$jar:${HADOOP_CLASSPATH}
done
7.在hive-site.xml中配置参数。
<property>
<name>hive.user.install.directory</name>
<value>/user/</value>
<description>
If hive (in tez mode only) cannot find a usable hive jar in "hive.jar.directory",
it will upload the hive jar to "hive.user.install.directory/user.name"
and use it to run queries.
</description>
</property>
<property>
<name>hive.execution.engine</name>
<value>tez</value>
<description>
Expects one of [mr, tez, spark].
Chooses execution engine. Options are: mr (Map reduce, default), tez, spark. While MR
remains the default engine for historical reasons, it is itself a historical engine
and is deprecated in Hive 2 line. It may be removed without further warning.
</description>
</property>
8.hive启动后执行。
set hive.execution.engine=tez; #即可运行hive on tez任务。
补充:hive2.x默认计算引擎为tez,编辑/usr/hive/conf/hive-site.xml
# Tez实际使用
配置tez到hive中,安装过程省略。
准备数据:
CREATE TABLE user_match_temp (
user_name string,
opponent string,
result int,
create_time timestamp)
row format delimited fields terminated by ','
stored as textfile
location '/project/rhett/user_match_temp/';
执行查询:
CREATE TABLE user_match_temp (
user_name string,
opponent string,
result int,
create_time timestamp)
row format delimited fields terminated by ','
stored as textfile
location '/project/rhett/user_match_temp/';
在tez界面可以查看对应的任务所有的DAG都在这里:
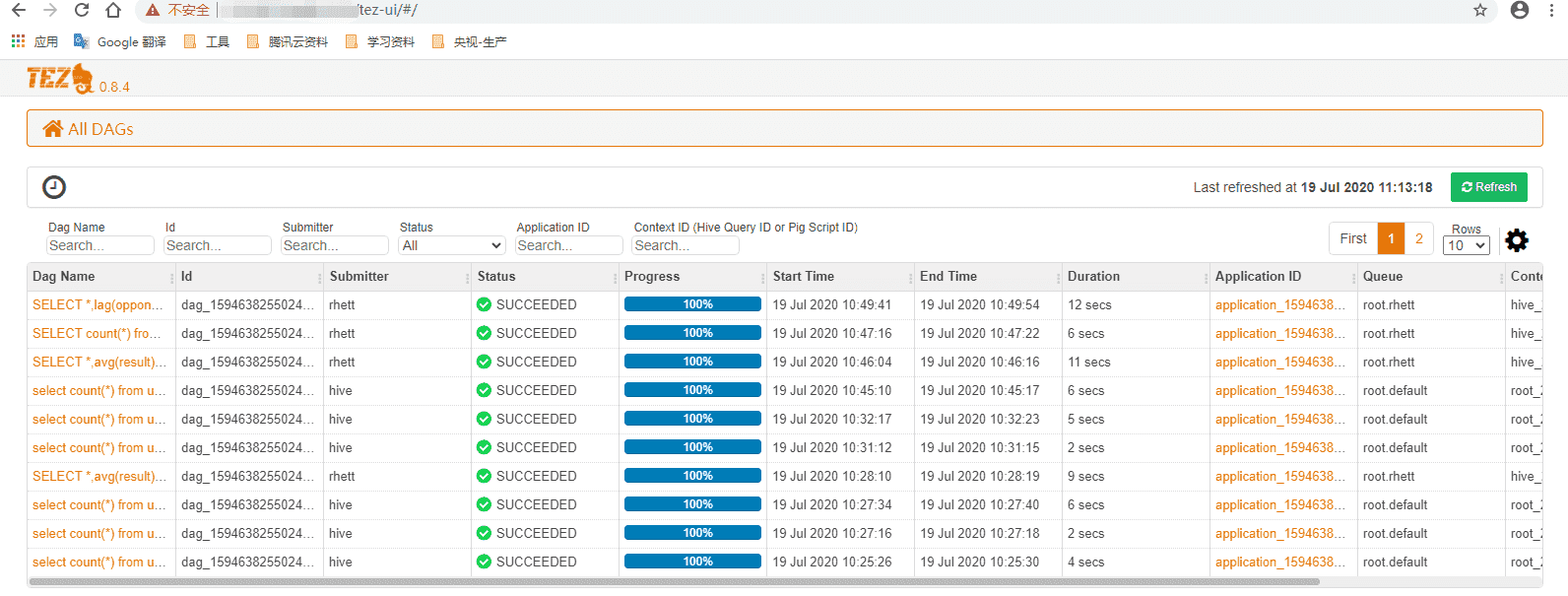
在上图可以查看到整个任务的执行调度情况。上图显示了执行结果,执行用户,执行语句,执行在yarn的applicationID还有队列。这里dag id也是惟一的id,点击dag name就会显示DAG的整个过程:
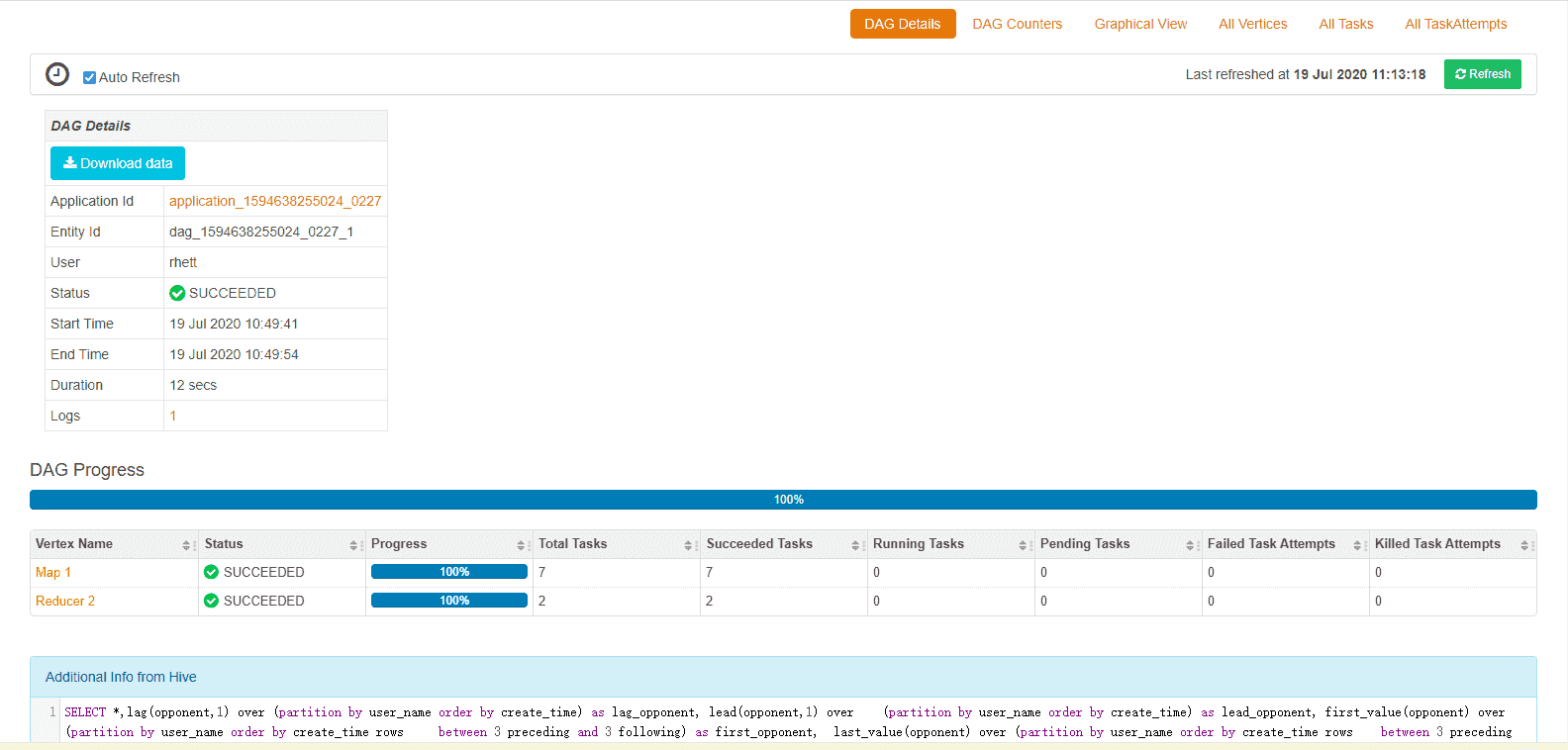
上图显示了 DAG的概述界面,运行进展,包含了2个Vertex,其中map vertex执行7个任务,reducer vertex执行2个任务,并且都是成功的,最下面是执行的完整sql语句。在最上面有一个下载的按钮,这个下载之后是一个zip的压缩包,压缩包主要是5个json文件,包含运行的任务的情况,dag的情况,task_attempts情况,tasks情况,vertex情况。
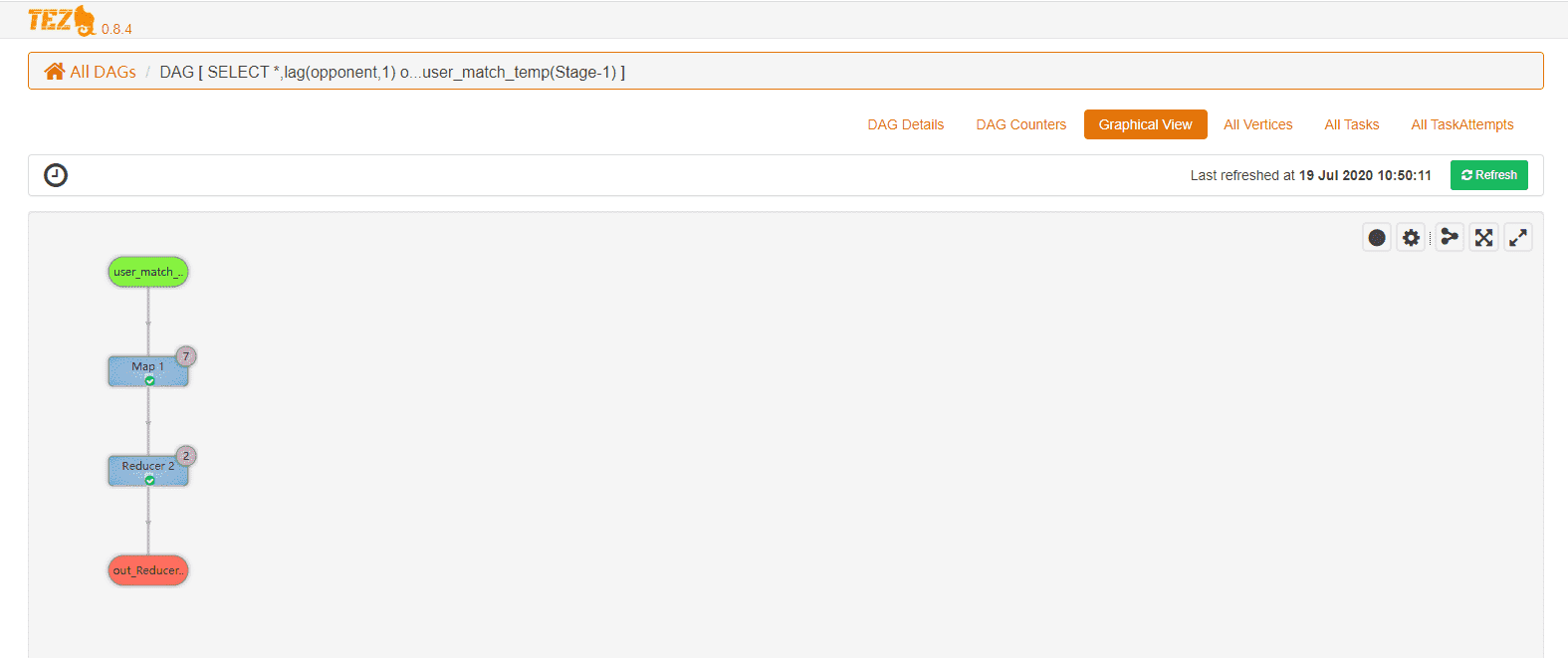
执行的DAG图形:
还可以查看所有的tez的所有任务:
# 总结
感谢大神分享:
https://zhuanlan.zhihu.com/p/63315907
https://blog.csdn.net/hqwang4/article/details/78090087
https://cloud.tencent.com/developer/article/1625679
https://cwiki.apache.org/confluence/display/TEZ/How+initial+task+parallelism+works
https://www.jianshu.com/p/167ba0464a44
# 参考文章
- https://www.cnblogs.com/boanxin/p/13336930.html










