TIP
本文主要是介绍 Pytorch-基础入门介绍 。
- pytorch简介
- 一.Pytorch是什么?
- 二.为什么选择 Pytorch?
- 三.PyTorch 的架构是怎样的?
- 四.Pytorch 与 tensorflow 之间的差异在哪里?
- 五.Pytorch有哪些常用工具包?
- 【----------------------------】
- Pytorch 基本概念
- 张量(Tensor)
- 变量(Variable)
- 数据集(dataset)
- PyTorch 优化
- 【----------------------------】
- PyTorch基础知识总结
- Tensor(张量)
- Autograd
- 神经网络包nn (torch.nn)
- 损失函数
- 优化器(torch.optim)
- 数据的加载和预处理
- Dataset(torch.utils.data.Dataset)
- DataLoader(torch.utils.data.DataLoader)
- 参考文章
# pytorch简介
# 一.Pytorch是什么?
Pytorch是torch的python版本,是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程。Torch 是一个经典的对多维矩阵数据进行操作的张量(tensor )库,在机器学习和其他数学密集型应用有广泛应用。与Tensorflow的静态计算图不同,pytorch的计算图是动态的,可以根据计算需要实时改变计算图。但由于Torch语言采用 Lua,导致在国内一直很小众,并逐渐被支持 Python 的 Tensorflow 抢走用户。作为经典机器学习库 Torch 的端口,PyTorch 为 Python 语言使用者提供了舒适的写代码选择。
# 二.为什么选择 Pytorch?
# 1.简洁:
PyTorch的设计追求最少的封装,尽量避免重复造轮子。不像 TensorFlow 中充斥着session、graph、operation、name_scope、variable、tensor、layer等全新的概念,PyTorch 的设计遵循tensor→variable(autograd)→nn.Module 三个由低到高的抽象层次,分别代表高维数组(张量)、自动求导(变量)和神经网络(层/模块),而且这三个抽象之间联系紧密,可以同时进行修改和操作。 简洁的设计带来的另外一个好处就是代码易于理解。PyTorch的源码只有TensorFlow的十分之一左右,更少的抽象、更直观的设计使得PyTorch的源码十分易于阅读。
# 2.速度:
PyTorch 的灵活性不以速度为代价,在许多评测中,PyTorch 的速度表现胜过 TensorFlow和Keras 等框架。框架的运行速度和程序员的编码水平有极大关系,但同样的算法,使用PyTorch实现的那个更有可能快过用其他框架实现的。
# 3.易用:
PyTorch 是所有的框架中面向对象设计的最优雅的一个。PyTorch的面向对象的接口设计来源于Torch,而Torch的接口设计以灵活易用而著称,Keras作者最初就是受Torch的启发才开发了Keras。PyTorch继承了Torch的衣钵,尤其是API的设计和模块的接口都与Torch高度一致。PyTorch的设计最符合人们的思维,它让用户尽可能地专注于实现自己的想法,即所思即所得,不需要考虑太多关于框架本身的束缚。
# 4.活跃的社区:
PyTorch 提供了完整的文档,循序渐进的指南,作者亲自维护的论坛 供用户交流和求教问题。Facebook 人工智能研究院对 PyTorch 提供了强力支持,作为当今排名前三的深度学习研究机构,FAIR的支持足以确保PyTorch获得持续的开发更新,不至于像许多由个人开发的框架那样昙花一现。
# 三.PyTorch 的架构是怎样的?
PyTorch(Caffe2) 通过混合前端,分布式训练以及工具和库生态系统实现快速,灵活的实验和高效生产。PyTorch 和 TensorFlow 具有不同计算图实现形式,TensorFlow 采用静态图机制(预定义后再使用),PyTorch采用动态图机制(运行时动态定义)。PyTorch 具有以下高级特征:
- 混合前端:新的混合前端在急切模式下提供易用性和灵活性,同时无缝转换到图形模式,以便在C ++运行时环境中实现速度,优化和功能。
- 分布式训练:通过利用本地支持集合操作的异步执行和可从Python和C ++访问的对等通信,优化了性能。
- Python优先: PyTorch为了深入集成到Python中而构建的,因此它可以与流行的库和Cython和Numba等软件包一起使用。
- 丰富的工具和库:活跃的研究人员和开发人员社区建立了丰富的工具和库生态系统,用于扩展PyTorch并支持从计算机视觉到强化学习等领域的开发。
- 本机ONNX支持:以标准ONNX(开放式神经网络交换)格式导出模型,以便直接访问与ONNX兼容的平台,运行时,可视化工具等。
- C++前端:C++前端是PyTorch的纯C++接口,它遵循已建立的Python前端的设计和体系结构。它旨在实现高性能,低延迟和裸机C++应用程序的研究。 使用GPU和CPU优化的深度学习张量库。
# 四.Pytorch 与 tensorflow 之间的差异在哪里?
上面也将了PyTorch 最大优势是建立的神经网络是动态的, 对比静态的 Tensorflow, 它能更有效地处理一些问题, 比如说 RNN 变化时间长度的输出。各有各的优势和劣势。两者都是大公司发布的, Tensorflow(Google)宣称在分布式训练上下了很大的功夫, 那就默认 Tensorflow 在分布式训练上要超出 Pytorch(Facebook),还有tensorboard可视化工具, 但是 Tensorflow 的静态计算图使得在 RNN 上有一点点被动 (虽然它用其他途径解决了), 不过用 PyTorch 的时候, 会对这种动态的 RNN 有更好的理解。而且 Tensorflow 的高度工业化, 它的底层代码很难看懂, Pytorch 好那么一点点, 如果深入 PytorchAPI, 至少能比看 Tensorflow 多看懂一点点 Pytorch 的底层在干啥。
# 五.Pytorch有哪些常用工具包?
- torch :类似 NumPy 的张量库,强 GPU 支持 ;
- torch.autograd :基于 tape 的自动区别库,支持 torch 之中的所有可区分张量运行;
- torch.nn :为最大化灵活性未涉及、与 autograd 深度整合的神经网络库;
- torch.optim:与 torch.nn 一起使用的优化包,包含 SGD、RMSProp、LBFGS、Adam 等标准优化方式;
- torch.multiprocessing: python 多进程并发,进程之间 torch Tensors 的内存共享;
- torch.utils:数据载入器。具有训练器和其他便利功能;
- torch.legacy(.nn/.optim) :处于向后兼容性考虑,从 Torch 移植来的 legacy 代码;
# 【----------------------------】
# Pytorch 基本概念
# 张量(Tensor)
PyTorch 张量(Tensor),张量是PyTorch最基本的操作对象,英文名称为Tensor,它表示的是一个多维的矩阵。比如零维是一个点,一维就是向量,二维就是一般的矩阵,多维就相当于一个多维的数组,这和numpy是对应的,而且 Pytorch 的 Tensor 可以和 numpy 的ndarray相互转换,唯一不同的是Pytorch可以在GPU上运行,而numpy的 ndarray 只能在CPU上运行。
常用的不同数据类型的 Tensor 如下:
- 32位浮点型 torch.FloatTensor
- 64位浮点型 torch.DoubleTensor
- 16位整型 torch.ShortTensor
- 32位整型 torch.IntTensor
- 64位整型 torch.LongTensor
# 变量(Variable)
Variable,也就是变量,这个在numpy里面是没有的,是神经网络计算图里特有的一个概念,就是Variable提供了自动求导的功能,之前如果了解Tensorflow的读者应该清楚神经网络在做运算的时候需要先构造一个计算图谱,然后在里面运行前向传播和反向传播。
Variable和Tensor本质上没有区别,不过Variable会被放入一个计算图中,然后进行前向传播,反向传播,自动求导。
首先Variable是在torch.autograd.Variable中,要将一个tensor变成Variable也非常简单,比如想让一个tensor a变成Variable,只需要Variable(a)就可以了。Variable的属性如下:
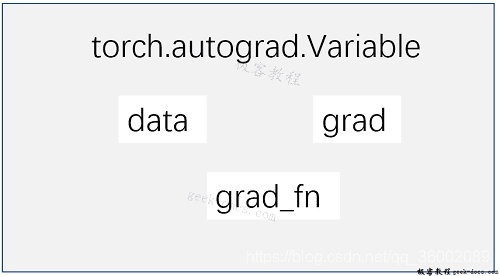
Variable 有三个比较重要的组成属性:data、grad和grad_fn。通过data可以取出 Variable 里面的tensor数值,grad_fn表示的是得到这个Variable的操作。比如通过加减还是乘除来得到的,最后grad是这个Variable的反向传播梯度。
构建Variable,要注意得传入一个参数requires_grad=True,这个参数表示是否对这个变量求梯度,默认的是False,也就是不对这个变量求梯度,这里我们希望得到这些变量的梯度,所以需要传入这个参数。
y.backward(),这一行代码就是所谓的自动求导,这其实等价于y.backward(torch.FloatTensor([1])),只不过对于标量求导里面的参数就可以不写了,自动求导不需要你再去明确地写明哪个函数对哪个函数求导,直接通过这行代码就能对所有的需要梯度的变量进行求导,得到它们的梯度,然后通过x.grad可以得到x的梯度。
矩阵求导,相当于给出了一个三维向量去做运算,这时候得到的结果y就是一个向量,这里对这个向量求导就不能直接写成y.backward(),这样程序就会报错的。这个时候需要传入参数声明,比如y.backward(troch.FloatTensor([1, 1, 1])),这样得到的结果就是它们每个分量的梯度,或者可以传入y.backward(torch.FloatTensor([1, 0.1, 0.01])),这样得到的梯度就是它们原本的梯度分别乘上1, 0.1 和 0.01。
# 数据集(dataset)
数据读取和预处理是进行机器学习的首要操作,PyTorch提供了很多方法来完成数据的读取和预处理。本文介绍 Dataset,TensorDataset,DataLoader,ImageFolder的简单用法。
# torch.utils.data.Dataset
torch.utils.data.Dataset是代表这一数据的抽象类。你可以自己定义你的数据类,继承和重写这个抽象类,非常简单,只需要定义__len__和__getitem__这个两个函数:
from torch.utils.data import Dataset
import pandas as pd
class myDataset(Dataset):
def __init__(self,csv_file,txt_file,root_dir, other_file):
self.csv_data = pd.read_csv(csv_file)
with open(txt_file,'r') as f:
data_list = f.readlines()
self.txt_data = data_list
self.root_dir = root_dir
def __len__(self):
return len(self.csv_data)
def __gettime__(self,idx):
data = (self.csv_data[idx],self.txt_data[idx])
return data
通过上面的方式,可以定义我们需要的数据类,可以通过迭代的方式来获取每一个数据,但这样很难实现取batch,shuffle或者是多线程去读取数据。
# torch.utils.data.TensorDataset
torch.utils.data.TensorDataset 继承自 Dataset,新版把之前的data_tensor和target_tensor去掉了,输入变成了可变参数,也就是我们平常使用*args。
原版使用方法
train_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 新版使用方法
train_dataset = Data.TensorDataset(x,y)
使用 TensorDataset 的方法可以参考下面的例子:
import torch
import torch.utils.data as Data
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(10, 1, 10)
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=0,
)
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ', batch_x.numpy(), '| batch y: ', batch_y.numpy())
执行结果:

# torch.utils.data.DataLoader
PyTorch中提供了一个简单的办法来做这个事情,通过torch.utils.data.DataLoader来定义一个新的迭代器,如下:
from torch.utils.data import DataLoader
dataiter = DataLoader(myDataset,batch_size=32,shuffle=True,collate_fn=defaulf_collate)
其中的参数都很清楚,只有 collate_fn 是标识如何取样本的,我们可以定义自己的函数来准确地实现想要的功能,默认的函数在一般情况下都是可以使用的。 需要注意的是,Dataset类只相当于一个打包工具,包含了数据的地址。真正把数据读入内存的过程是由Dataloader进行批迭代输入的时候进行的。
# torchvision.datasets.ImageFolder
另外在torchvison这个包中还有一个更高级的有关于计算机视觉的数据读取类:ImageFolder,主要功能是处理图片,且要求图片是下面这种存放形式:
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/asd/png
root/cat/zxc.png
之后这样来调用这个类:
from torchvision.datasets import ImageFolder
dset = ImageFolder(root='root_path', transform=None, loader=default_loader)
其中 root 需要是根目录,在这个目录下有几个文件夹,每个文件夹表示一个类别:transform 和 target_transform 是图片增强,后面我们会详细介绍;loader是图片读取的办法,因为我们读取的是图片的名字,然后通过 loader 将图片转换成我们需要的图片类型进入神经网络。
# PyTorch 优化
优化算法就是一种调整模型参数更新的策略,在深度学习和机器学习中,我们常常通过修改参数使得损失函数最小化或最大化。
优化算法分为两大类:
# (1) 一阶优化算法
这种算法使用各个参数的梯度值来更新参数,最常用的一阶优化算法是梯度下降。所谓的梯度就是导数的多变量表达式,函数的梯度形成了一个向量场,同时也是一个方向,这个方向上方向导数最大,且等于梯度。梯度下降的功能是通过寻找最小值,控制方差,更新模型参数,最终使模型收敛,网络的参数更新公式如下:

# (2) 二阶优化算法
二阶优化算法是用来二阶导数(也叫做Hessian方法)来最小化或最大化损失函数,主要基于牛顿法,但由于二阶导数的计算成本很高,所以这种方法并没有广泛使用。torch.optim是一个实现了各种优化算法的库,多数常见的算法都能直接通过这个包来调用,并且接口具备足够的通用性,使得未来能够集成更加复杂的方法,比如随机梯度下降,以及添加动量的随机梯度下降,自适应学习率等。为了构建一个Optimizer,你需要给它一个包含了需要优化的参数(必须都是Variable对象)的iterable。然后设置optimizer的参数选项,比如学习率,动量等等。
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # reproducible
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
# fake dataset
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
# plot dataset
plt.scatter(x.numpy(), y.numpy())
plt.show()
执行结果如下:
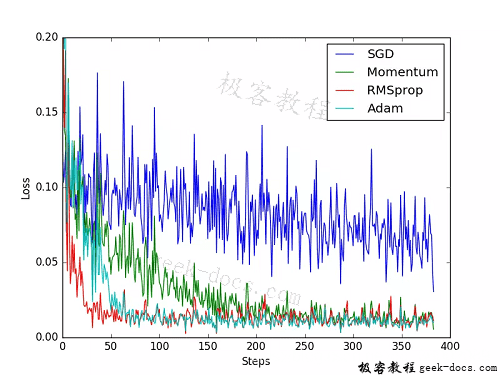
为了对比每一种优化器, 我们给他们各自创建一个神经网络, 但这个神经网络都来自同一个 Net 形式。接下来在创建不同的优化器, 用来训练不同的网络. 并创建一个 loss_func 用来计算误差。几种常见的优化器:SGD, Momentum, RMSprop, Adam。
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0,)
# 默认的 network 形式
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x
# 为每个优化器创建一个 net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # 记录 training 时不同神经网络的 loss
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x) # 务必要用 Variable 包一下
b_y = Variable(batch_y)
# 对每个优化器, 优化属于他的神经网络
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.item()) # loss recoder
训练和 loss 画图,结果如下:
# 【----------------------------】
# PyTorch基础知识总结
# Tensor(张量)
张量是PyTorch里的基本运算单位,与numpy的ndarray相同都表示一个多维的矩阵。与ndarray最大的区别在于Tensor能使用GPU加速,而ndarray只能用在CPU上。
# 与Numpy之间进行转换
将Tensor转换成numpy,只需调用.numpy()方法即可。
将numpy转换成Tensor,使用torch.from_numpy()进行转换。
# a --> Tensor
a = torch.rand(3, 2)
# Tensor --> numpy
numpy_a = a.numpy()
# numpy --> Tensor
b = torch.from_numpy(numpy_a)
# Tensor初始化
- torch.rand(*size) : 使用[0, 1]均匀分布随机初始化
- torch.randn(*size) : 服从正太分布初始化
- torch.zeros(*size) : 使用0填充
- torch.ones(*size):使用1填充
- torch.eye(*size) :初始化一个单位矩阵,即对角线为1,其余为0
# Autograd
PyTorch中的Autograd模块实现了深度学习的算法中的反向传播求导数,在Tensor上的所有操作,Autograd都能为它们自动计算微分,简化了手动求导数的过程。
在张量创建时,通过设置requires_grad = True来告诉PyTorch需要对该张量进行自动求导,PyTorch会记录该张量的每一步操作历史并自动计算导数。requires_grad默认为False。
x = torch.randn(5, 5, requires_grad = True)
在计算完成后,调用backward()方法会自动根据历史操作来计算梯度,并保存在grad中。
# 神经网络包nn (torch.nn)
torch.nn是专门为神经网络设计的模块化接口,建立在Autogard之上。
通常定义一个神经网络类除了使用到nn之外还会引用nn.functional,这个包中包含了神经网络中使用的一些常见函数(ReLu, pool, sigmoid, softmax等),这些函数一般放在forward函数中。
通常一个神经网络类需要继承nn.Module,并实现forward方法,PyTorch就会根据autograd自动实现backward方法。下面是LeNet网络模型的定义。
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 卷积层
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 全连接层
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 卷积 --> ReLu --> 池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), (2, 2))
# reshape, '-1'表示自适应
# x = (n * 16 * 5 * 5) --> n : batch size
# x.size()[0] == n --> batch size
x = x.view(x.size()[0], -1)
# 全连接层
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 损失函数
在torch.nn中还定义了一些常用的损失函数,比如MESLoss(均方误差),CrossEntropyLoss(交叉熵误差)等。
labels = torch.arange(10).view(1, 10).float()
out = net(input)
criterion = nn.MSELoss()
# 计算loss
loss = criterion(labels, out)
# 优化器(torch.optim)
在反向传播计算完所有参数的梯度后,还需要使用优化方法来更新网络的参数,常用的优化方法有随机梯度下降法(SGD),策略如下:
weight = weight - learning_rate * gradient
import torch.optim
import torch.nn as nn
out = net(input)
criterion = nn.MSELoss(out, labels)
# 新建一个优化器,SGD只需要输入要调整的参数和学习率
optimizer = torch.optim.SGD(net.parameters(), lr = 0.01)
# 反向传播前,先梯度清0, optimizer.zero_grad()等同于net.zero_grad()
optimizer.zero_grad()
loss.backward()
# 更新参数
optimizer.step()
# 数据的加载和预处理
PyTorch通过torch.utils.data对一般常用的数据加载进行了封装,可以很容易实现数据预处理和批量加载。torchvision已经有一些常用的数据集以及训练好的模型(例如,CIFAR-10, ImageNet, COCO等),可以很方便的在这些模型上进行训练以及测试。
# Dataset(torch.utils.data.Dataset)
为了方便数据的读取,通常需要将使用的数据集包装为Dataset类。可以使用torchvision.dataset包中存在数据集来生成Dataset,同时也可以自定义Dataset类。
以torchvision.dataset中MNIST数据集为例生成dataset
dataset = tv.datasets.MNIST(
root='data/',
train=True,
download=True,
transform=None
)
自定义Dataset,当torchvision.dataset包中没有相应的数据集,这时候就需要我们自定义Dataset类了,自定义类必须继承于torch.utils.data.Dataset类,并且实现__ len __ () 和 __ getitem __ () 方法。
- __ len __ () 该方法返回数据集的总长度。
- __ getitem __ () 该方法通过索引[0, len(self) - 1]来获取一条数据或者一个样本。
# DataLoader(torch.utils.data.DataLoader)
DataLoader为我们提供了对Dataset的读取操作,常用的参数有batch_size(每一批数据的大小), shuffle(是否进行随机读取操作), num_workers(加载数据的时候使用几个子进程)
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_works=0)
# trainloader是一个可迭代的对象,我们可以使用iter分次获取数据。
# 但是通常使用for循环来对其进行遍历,如下。
for i, data in enumerate(trainloader):
# deal the data
pass
此时,我们可以通过Dataset加装数据集,并使用DataLoader来遍历处理数据。
torchvision包
torchvision是专门用来处理图像的库,里面有datasets, models, transforms等类,其中最常用的类是transforms,它通常用来进行数据的预处理(ToTensor, 归一化等),如下。
from torchvision import transforms as transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.229, 0.224, 0.225)), #R,G,B每层的归一化用到的均值和方差
])
# 参考文章
- https://blog.csdn.net/bestrivern/article/details/89433023
- https://www.cnblogs.com/phonyhao/p/14167467.html
- https://blog.csdn.net/qq_36002089/article/details/118652105










