TIP
本文主要是介绍 Spark-综合配置优化 。
对于构建好的 Flink 集群,如何能够有效地进行集群以及任务方面的监控与优化是非常重要的,尤其对于 7*24 小时运行的生产环境。重点介绍 Checkpointing 的监控。然后通过分析各种监控指标帮助用户更好地对 Flink 应用进行性能优化,以提高 Flink 任务执行的数据处理性能和效率。
# 一、Checkpoint 页面监控与优化
Flink Web页面中也提供了针对 Job Checkpointing 相关的监控信息,Checkpointing监控页面中共有 Overview、History、Summary 和 Configuration 四个页签,分别对Checkpointing 从不同的角度进行了监控,每个页面中都包含了与 Checkpointing 相关的指标。
# 1.1、Overview 页签
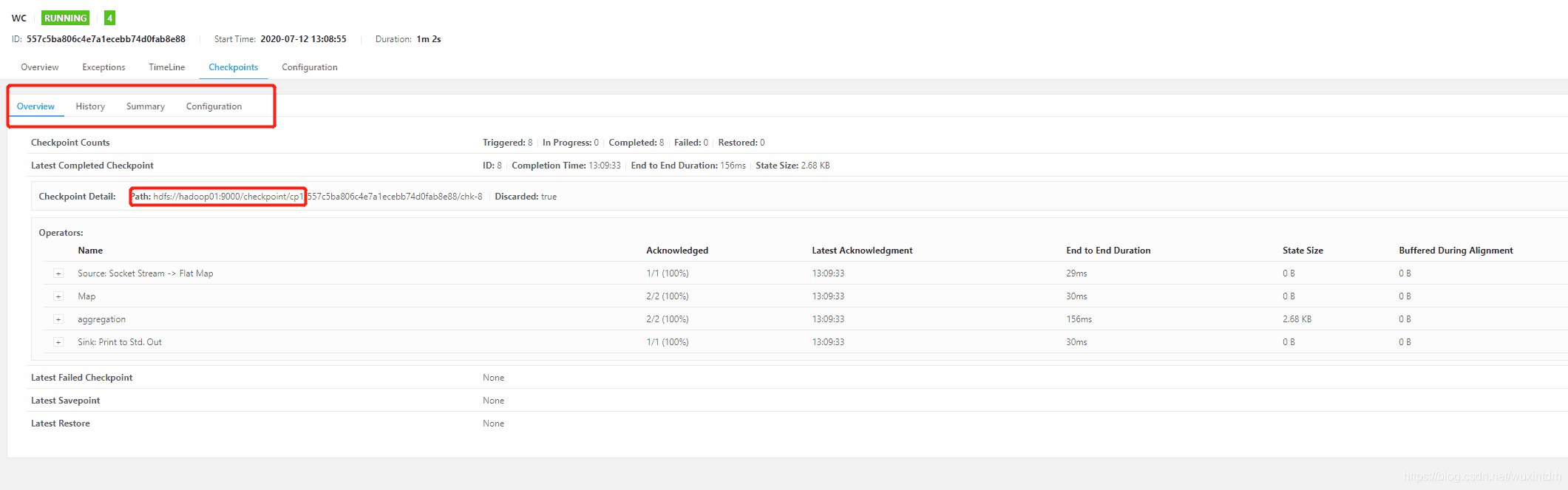
Overview 页签中宏观地记录了 Flink 应用中 Checkpoints 的数量以及 Checkpoint 的最新记录,包括失败和完成的 Checkpoints 记录。
- Checkpoint Counts:包含了触发、进行中、完成、失败、重置等 Checkpoint 状态数量统计。
- Latest Completed Checkpoint:记录了最近一次完成的 Checkpoint 信息,包括结束时间,端到端时长,状态大小等。
- Latest Failed Checkpoint:记录了最近一次失败的 Checkpoint 信息。
- Latest Savepoint:记录了最近一次 Savepoint 触发的信息。
- Latest Restore:记录了最近一次重置操作的信息,包括从 Checkpoint 和 Savepoint两种数据中重置恢复任务
# 1.2、Configuration页签
Configuration 页签中包含 Checkpoints 中所有的基本配置,具体的配置解释如下:
- Checkpointing Mode:标记 Checkpointing 是 Exactly Once 还是 At Least Once 的模式。
- Interval: Checkpointing 触 发 的 时 间 间 隔 , 时 间 间 隔 越 小 意 味 着 越 频 繁 的Checkpointing。
- Timeout: Checkpointing 触发超时时间,超过指定时间 JobManager 会取消当次Checkpointing,并重新启动新的 Checkpointing。
- Minimum Pause Between Checkpoints:配置两个 Checkpoints 之间最短时间间隔,当上一次 Checkpointing 结束后,需要等待该时间间隔才能触发下一次 Checkpoints,避免触发过多的 Checkpoints 导致系统资源被消耗。
- Persist Checkpoints Externally:如果开启 Checkpoints,数据将同时写到外部持久化存储中。
# 二、内存优化
在大数据领域,大多数开源框架(Hadoop、Spark、Storm)都是基于 JVM 运行,但是JVM 的内存管理机制往往存在着诸多类似 OutOfMemoryError 的问题,主要是因为创建过多的对象实例而超过 JVM 的最大堆内存限制,却没有被有效回收掉,这在很大程度上影响了系统的稳定性,尤其对于大数据应用,面对大量的数据对象产生,仅仅靠 JVM 所提供的各种垃圾回收机制很难解决内存溢出的问题。在开源框架中有很多框架都实现了自己的内存管理,例如 Apache Spark的Tungsten项目,在一定程度上减轻了框架对 JVM 垃圾回收机制的依赖,从而更好地使用 JVM 来处理大规模数据集。
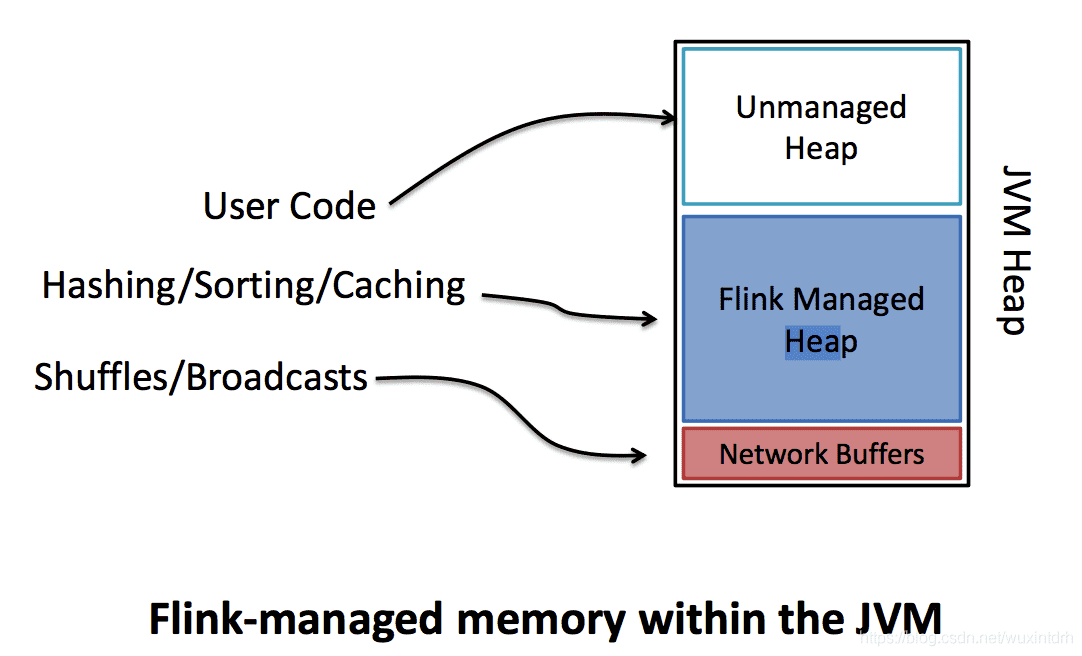
Flink 也基于 JVM 实现了自己的内存管理,将 JVM 根据内存区分为 Unmanned Heap、FlinkManaged Heap、Network Buffers 三个区域。在 Flink 内部对 Flink Managed Heap 进行管理,在启动集群的过程中直接将堆内存初始化成 Memory Pages Pool,也就是将内存全部以二进制数组的方式占用,形成虚拟内存使用空间。新创建的对象都是以序列化成二进制数据的方式存储在内存页面池中,当完成计算后数据对象 Flink 就会将 Page 置空,而不是通过JVM 进行垃圾回收,保证数据对象的创建永远不会超过 JVM 堆内存大小,也有效地避免了因为频繁 GC 导致的系统稳定性问题。
# 2.1、JobManager 配置
JobManager 在 Flink 系统中主要承担管理集群资源、接收任务、调度 Task、收集任务状态以及管理 TaskManager 的功能,JobManager 本身并不直接参与数据的计算过程中,因此 JobManager 的内存配置项不是特别多,只要指定 JobManager 堆内存大小即可。
jobmanager.heap.size:设定JobManager堆内存大小,默认为1024MB。
# 2.2、TaskManager 配置
TaskManager作为Flink集群中的工作节点,所有任务的计算逻辑均执行在TaskManager之上,因此对 TaskManager 内存配置显得尤为重要,可以通过以下参数配置对 TaskManager进行优化和调整。
- taskmanager.heap.size:设定 TaskManager 堆内存大小,默认值为 1024M,如果在 Yarn的集群中,TaskManager 取决于 Yarn 分配给 TaskManager Container 的内存大小,且Yarn 环境下一般会减掉一部分内存用于 Container 的容错。
- taskmanager.jvm-exit-on-oom:设定 TaskManager 是否会因为 JVM 发生内存溢出而停止,默认为 false,当 TaskManager 发生内存溢出时,也不会导致 TaskManager 停止。
- taskmanager.memory.size:设定 TaskManager 内存大小,默认为 0,如果不设定该值将会使用 taskmanager.memory.fraction 作为内存分配依据。
- taskmanager.memory.fraction:设定 TaskManager 堆中去除 Network Buffers 内存后的内存分配比例。该内存主要用于 TaskManager 任务排序、缓存中间结果等操作。例如,如果设定为 0.8,则代表 TaskManager 保留 80%内存用于中间结果数据的缓存,剩下 20%的 内 存 用 于创建用户定义函数中的数据对象存储 。 注 意 , 该参数只有 在taskmanage.memory.size 不设定的情况下才生效。
- taskmanager.memory.off-heap:设 置是 否开 启堆 外内 存供 Managed Memory 或 者Network Buffers 使用。
- taskmanager.memory.preallocate:设置是否在启动 TaskManager 过程中直接分配TaskManager 管理内存。
- taskmanager.numberOfTaskSlots:每个 TaskManager 分配的 slot 数量。
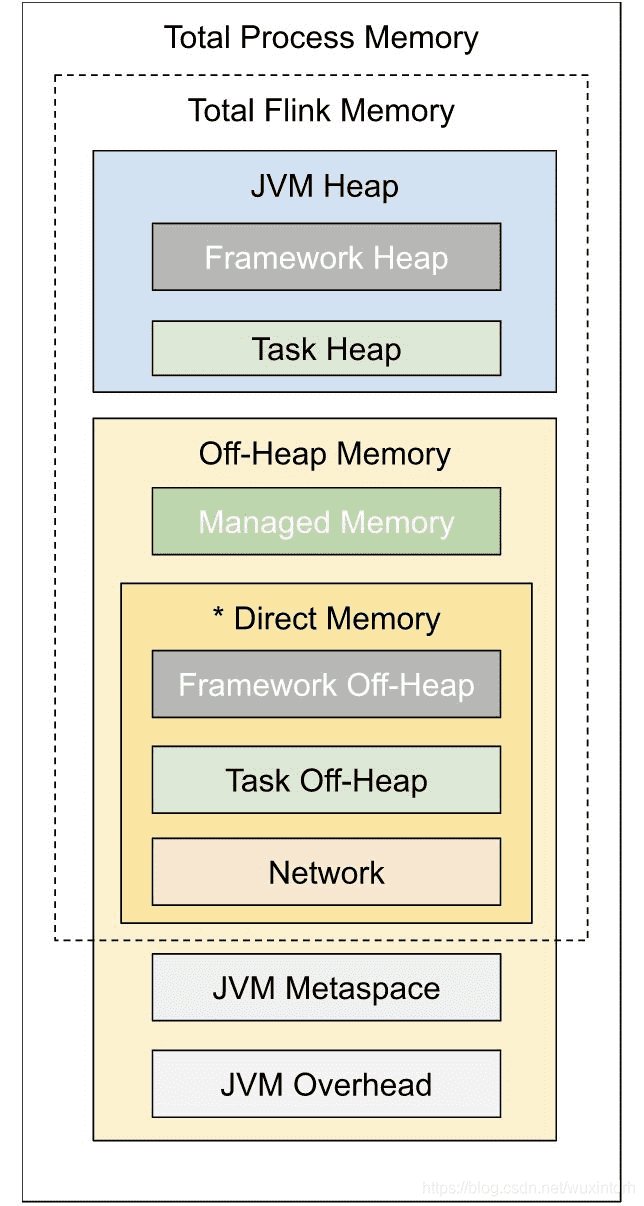
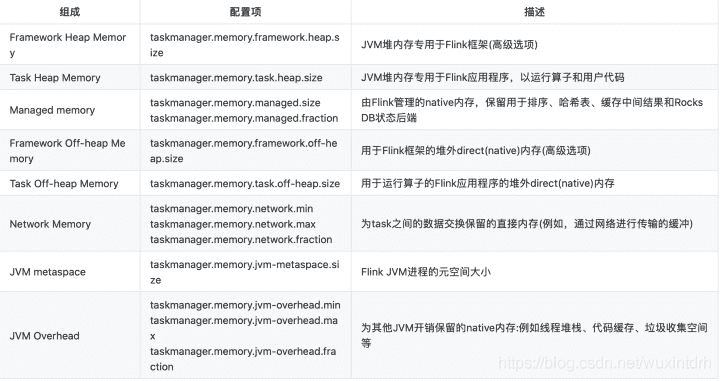
# 2.2.1、Flink1.10之后的内存模型
# 三、Flink 的网络缓存优化
Flink 将 JVM 堆内存切分为三个部分,其中一部分为 Network Buffers 内存。Network Buffers 内存是 Flink 数据交互层的关键内存资源,主要目的是缓存分布式数据处理过程中的输入数据。。通常情况下,比较大的 Network Buffers 意味着更高的吞吐量。如果系统出现“Insufficient number of network buffers”的错误,一般是因为 Network Buffers配置过低导致,因此,在这种情况下需要适当调整 TaskManager 上 Network Buffers 的内存大小,以使得系统能够达到相对较高的吞吐量。 目前 Flink 能够调整 Network Buffer 内存大小的方式有两种:一种是通过直接指定Network Buffers 内存数量的方式,另外一种是通过配置内存比例的方式。
# 3.1、设定 Network Buffer 内存数量(过时了)
直接设定 Nework Buffer 数量需要通过如下公式计算得出:
NetworkBuffersNum = total-degree-of-parallelism * intra-node-parallelism * n
其 中 total-degree-of-parallelism 表 示 每 个 TaskManager 的 总 并 发 数 量 ,intra-node-parallelism 表示每个 TaskManager 输入数据源的并发数量,n 表示在预估计算过程中 Repar-titioning 或 Broadcasting 操作并行的数量。intra-node-parallelism 通常情况下与 Task-Manager 的所占有的 CPU 数一致,且 Repartitioning 和 Broadcating 一般下不会超过 4 个并发。可以将计算公式转化如下:
NetworkBuffersNum = <slots-per-TM>^2 * < TMs>* 4
其中 slots-per-TM 是每个 TaskManager 上分配的 slots 数量,TMs 是 TaskManager 的总数量。对于一个含有 20 个 TaskManager,每个 TaskManager 含有 8 个 Slot 的集群来说,总共需要的 Network Buffer 数量为 8^2204=5120 个,因此集群中配置 Network Buffer内存的大小约为 300M 较为合适。计算完 Network Buffer 数量后,可以通过添加如下两个参数对 Network Buffer 内存进行配置。其中 segment-size 为每个 Network Buffer 的内存大小,默认为 32KB,一般不需要修改,通过设定 numberOfBuffers 参数以达到计算出的内存大小要求。
- taskmanager.network.numberOfBuffers:指定 Network 堆栈 Buffer 内存块的数量。
- taskmanager.memory.segment-size:内存管理器和Network栈使用的内存Buffer大小,默认为 32KB。
# 3.2、设定 Network 内存比例(推荐)
从 1.3 版本开始,Flink 就提供了通过指定内存比例的方式设置 Network Buffer 内存大小。
- taskmanager.network.memory.fraction: JVM 中用于 Network Buffers 的内存比例。
- taskmanager.network.memory.min: 最小的 Network Buffers 内存大小,默认为 64MB。
- taskmanager.network.memory.max: 最大的 Network Buffers 内存大小,默认 1GB。
- taskmanager.memory.segment-size: 内存管理器和 Network 栈使用的Buffer 大小,默认为 32KB。
# 参考文章
- https://blog.csdn.net/wuxintdrh/article/details/106662170










