TIP
本文主要是介绍 Spark-基础架构总结 。
# Spark简述及基本架构
# Spark简述
Spark发源于美国加州大学伯克利分校AMPLab的集群计算平台。它立足 于内存计算。从多迭代批量处理出发,兼收并蓄数据仓库、流处理和图计算等多种计算范式。
特点: 1、轻 Spark 0.6核心代码有2万行,Hadoop1.0为9万行,2.0为22万行。
2、快 Spark对小数据集能达到亚秒级的廷迟,这对于Hadoop MapReduce是无法想象的(因为”心跳”间隔机制,仅任务启动就有数秒的延迟)
3、灵 在实现层,它完美演绎了Scala trait动态混入策略(如可更换的集群调度器、序列化库); 在原语层,它同意扩展新的数据算子、新的数据源、新的language bindings(Java和Python)。 在范式层,Spark支持内存计算、多迭代批星处理、流处理和图计算等多种范式。
4、巧 巧在借势和借力。
Spark借Hadoop之势,与Hadoop无缝结合。
# 为什么Spark性能比Hadoop快?
1、Hadoop数据抽取运算模型
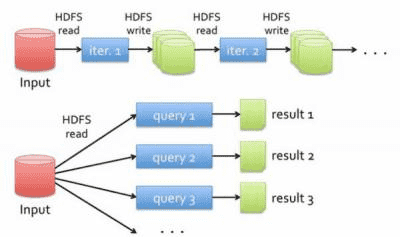
数据的抽取运算基于磁盘,中间结果也是存储在磁盘上。MR运算伴随着大量的磁盘IO。
2、Spark则使用内存取代了传统HDFS存储中间结果
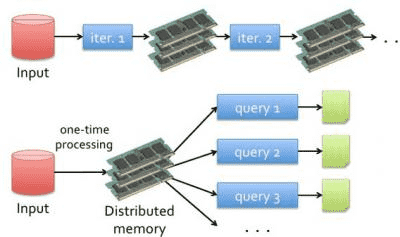
第一代的Hadoop全然使用hdfs存储中间结果,第二带的Hadoop增加了cache来保存中间结果。而Spark则是基于内存的中间数据集存储。能够将Spark理解为Hadoop的升级版本号,Spark兼容了Hadoop的API,而且能够读取Hadoop的数据文件格式,包含HDFS,Hbase等。
# Spark on Standalone执行过程(client模式)
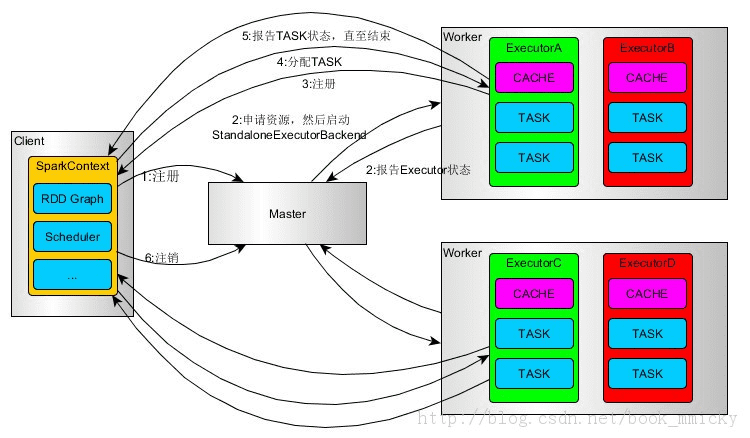
1、SparkContext连接到Master,向Master注冊并申请资源(CPU Core 和Memory)
2、Master依据SparkContext的资源申请要求和worker心跳周期内报告的信息决定在哪个worker上分配资源。然后在该worker上获取资源,然后启动StandaloneExecutorBackend。
3、StandaloneExecutorBackend向SparkContext注冊。
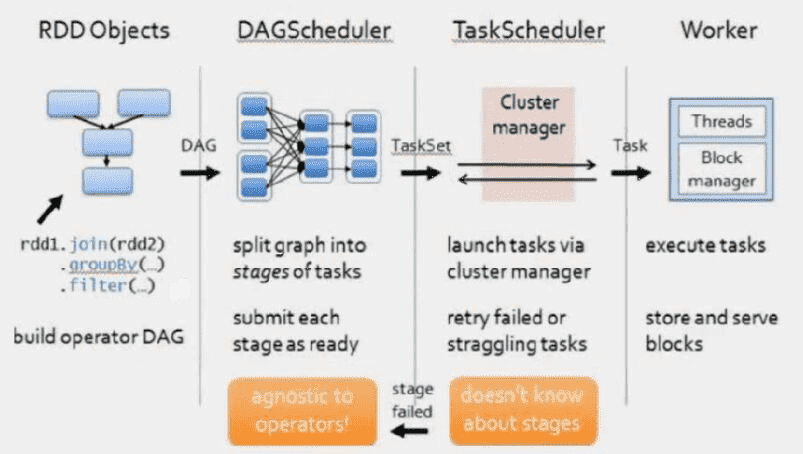
4、SparkContext将Applicaiton代码发StandaloneExecutorBackend;而且SparkContext解析Applicaiton代码,构建DAG图。并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job。每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生)。然后以Stage(或者称为TaskSet)提交给Task Scheduler, Task Scheduler负责将Task分配到对应的worker,最后提交给StandaloneExecutorBackend执行;
5、StandaloneExecutorBackend会建立executor 线程池。開始执行Task,并向SparkContext报告。直至Task完毕。
6、全部Task完毕后。SparkContext向Master注销。释放资源。
# Spark on YARN 执行过程(cluster模式)
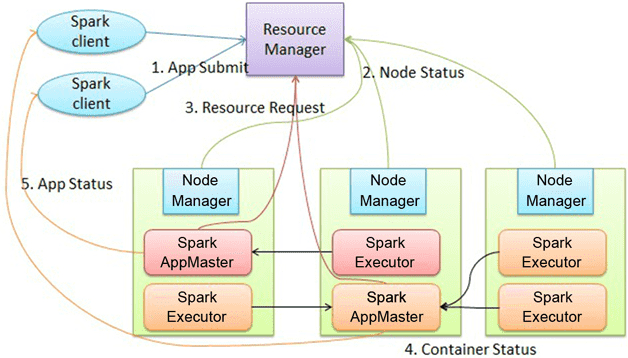
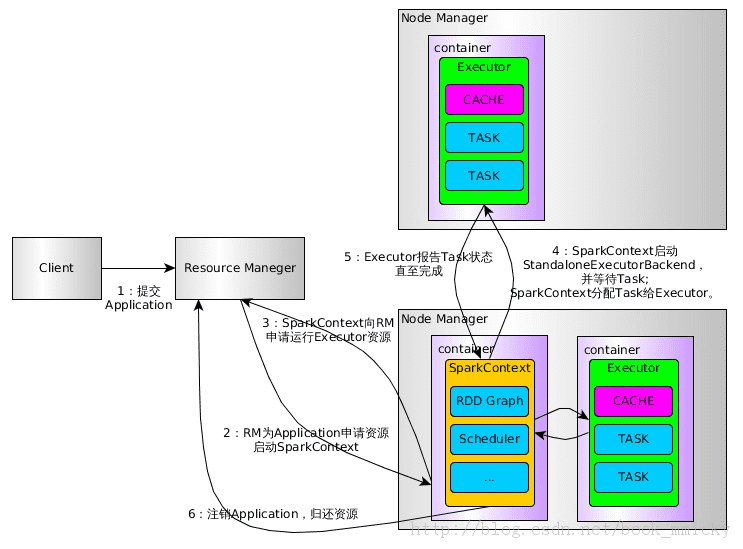
1、用户通过bin/spark-submit( Spark1.0.0 应用程序部署工具spark-submit)或 bin/spark-class 向YARN提交Application。
2、RM为Application分配第一个container,并在指定节点的container上启动SparkContext。
3、SparkContext向RM申请资源以执行Executor。
4、RM分配Container给SparkContext,SparkContext和相关的NM通讯,在获得的Container上启动StandaloneExecutorBackend,StandaloneExecutorBackend启动后,開始向SparkContext注冊并申请Task。
5、SparkContext分配Task给StandaloneExecutorBackend执行StandaloneExecutorBackend执行Task并向SparkContext汇报执行状况
6、Task执行完毕。SparkContext归还资源给RM,并注销退出。
# RDD简单介绍
RDD(Resilient Distributed Datasets)弹性分布式数据集,有例如以下几个特点: 1、它在集群节点上是不可变的、已分区的集合对象。
2、通过并行转换的方式来创建。如map, filter, join等。 3、失败自己主动重建。
4、能够控制存储级别(内存、磁盘等)来进行重用。
5、必须是可序列化的。
6、是静态类型的。
RDD本质上是一个计算单元。能够知道它的父计算单元。
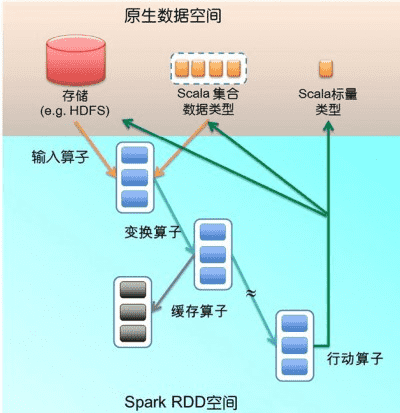

# RDD 是Spark进行并行运算的基本单位。RDD提供了四种算子:
1、输入算子:将原生数据转换成RDD,如parallelize、txtFile等
2、转换算子:最基本的算子,是Spark生成DAG图的对象。
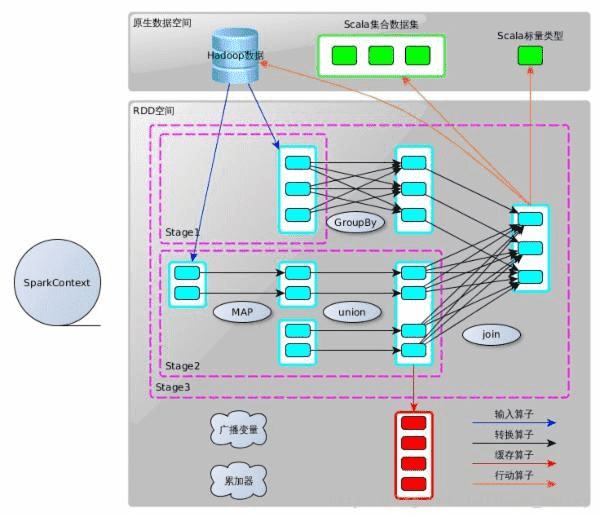
转换算子并不马上执行,在触发行动算子后再提交给driver处理,生成DAG图 –> Stage –> Task –> Worker执行。 按转化算子在DAG图中作用。能够分成两种:
窄依赖算子
- 输入输出一对一的算子,且结果RDD的分区结构不变,主要是map、flatMap;
- 输入输出一对一的算子,但结果RDD的分区结构发生了变化,如union、coalesce;
从输入中选择部分元素的算子。如filter、distinct、subtract、sample。
宽依赖算子
宽依赖会涉及shuffle类,在DAG图解析时以此为边界产生Stage。
- 对单个RDD基于key进行重组和reduce,如groupByKey、reduceByKey;
- 对两个RDD基于key进行join和重组。如join、cogroup。
3、缓存算子:对于要多次使用的RDD,能够缓冲加快执行速度,对关键数据能够採用多备份缓存。
4、行动算子:将运算结果RDD转换成原生数据,如count、reduce、collect、saveAsTextFile等。
# wordcount样例:
1、初始化。构建SparkContext。
val ssc=new SparkContext(args(0),"WordCount",System.getenv("SPARK_HOME"),Seq(System.getenv("SPARK_EXAMPLES_JAR")))
2、输入算子
val lines=ssc.textFlle(args(1))
3、变换算子
val words=lines.flatMap(x=>x.split(" "))
4、缓存算子
words.cache() //缓存
5、变换算子
val wordCounts=words.map(x=>(x,1))
val red=wordCounts.reduceByKey((a,b)=>{a+b})
6、行动算子
red.saveAsTextFile("/root/Desktop/out")
# RDD支持两种操作:
转换(transformation)从现有的数据集创建一个新的数据集 动作(actions)在数据集上执行计算后,返回一个值给驱动程序
比如。map就是一种转换,它将数据集每个元素都传递给函数,并返回一个新的分布数据集表示结果。而reduce是一种动作。通过一些函数将全部的元素叠加起来,并将终于结果返回给Driver程序。(只是另一个并行的reduceByKey。能返回一个分布式数据集)
Spark中的全部转换都是惰性的,也就是说,他们并不会直接计算结果。相反的。它们仅仅是记住应用到基础数据集(比如一个文件)上的这些转换动作。**仅仅有当发生一个要求返回结果给Driver的动作时,这些转换才会真正执行。**这个设计让Spark更加有效率的执行。 比如我们能够实现:通过map创建的一个新数据集,并在reduce中使用,终于仅仅返回reduce的结果给driver,而不是整个大的新数据集。
**默认情况下,**每个转换过的RDD都会在你在它之上执行一个动作时被又一次计算。
只是。你也能够使用persist(或者cache)方法,持久化一个RDD在内存中。
在这样的情况下,Spark将会在集群中。保存相关元素。下次你查询这个RDD时。它将能更高速訪问。
在磁盘上持久化数据集或在集群间复制数据集也是支持的。
Spark中支持的RDD转换和动作

注意: 有些操作仅仅对键值对可用,比方join。
另外。函数名与Scala及其它函数式语言中的API匹配,比如,map是一对一的映射,而flatMap是将每个输入映射为一个或多个输出(与MapReduce中的map相似)。
除了这些操作以外,用户还能够请求将RDD缓存起来。而且。用户还能够通过Partitioner类获取RDD的分区顺序,然后将另一个RDD依照相同的方式分区。有些操作会自己主动产生一个哈希或范围分区的RDD,像groupByKey,reduceByKey和sort等。
# 执行和调度
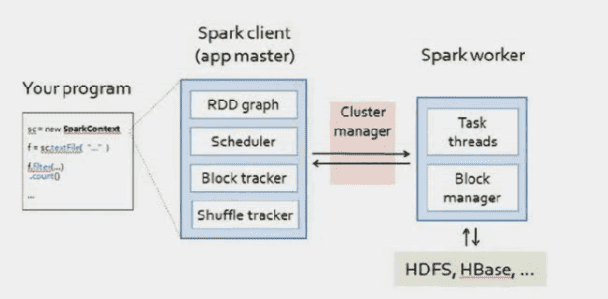
第一阶段记录变换算子序列、增带构建DAG图。
第二阶段由行动算子触发,DAGScheduler把DAG图转化为作业及其任务集。Spark支持本地单节点执行(开发调试实用)或集群执行。对于集群执行,客户端执行于master带点上,通过Cluster manager把划分好分区的任务集发送到集群的worker/slave节点上执行。
配置
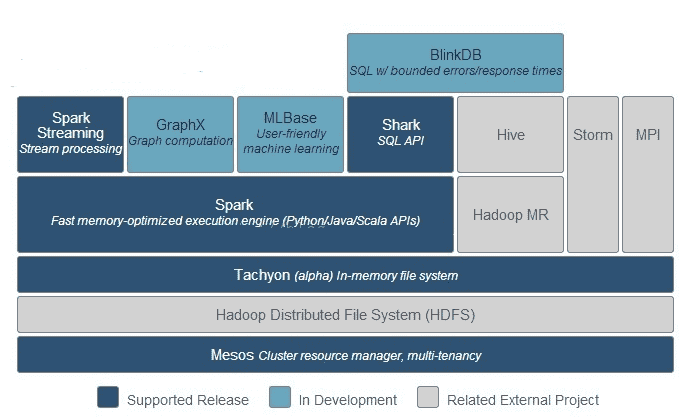
# Spark生态系统
# 参考文章
- https://www.cnblogs.com/bhlsheji/p/5153108.html










