TIP
本文主要是介绍 Sklearn-基础入门介绍 。
# sklearn 【对传统的机器学习和数据挖掘比较友好】
SciKit learn的简称是SKlearn,是一个开源的python库,专门用于机器学习、数据挖掘和数据分析的模块。它建立在 NumPy ,SciPy 和 matplotlib 上。
来源:https://www.zhihu.com/question/53740695
Tensorflow和Caffe、MXNet等是针对深度学习特制的工具包,而Scikit-learn是对传统的机器学习,包括预处理,特征工程,模型构建,验证等的完整实现。这两类工具压根不是做同一件事的。
说实话,即使现在深度学习大行其道,很多时候你还是要用传统机器学习方法解决问题的。首先不是每个人都有一个彪悍的电脑/服务器,其次,大多数问题真的不需要深度网络。最后,只会调用工具包的程序员不是好的机器学习者。
# sklearn 官方文档和网站
scikit-learn 中文社区官网: https://scikit-learn.org.cn/
scikit-learn 中文社区官网 (opens new window)
# 分类
标识对象所属的类别。
- 应用范围: 垃圾邮件检测,图像识别。
- 算法: SVM 最近邻 随机森林

# 回归
预测与对象关联的连续值属性。
- 应用范围: 药物反应,股票价格。
- 算法: SVR 最近邻 随机森林
# 聚类
自动将相似对象归为一组。
- 应用: 客户细分,分组实验成果。
- 算法: K-均值 谱聚类 MeanShift

# 降维
减少要考虑的随机变量的数量。
- 应用: 可视化,提高效率。
- 算法: K-均值 特征选择 非负矩阵分解

# 模型选择
比较,验证和选择参数和模型。
- 应用: 通过参数调整改进精度。
- 算法: 网格搜索 交叉验证 指标
# 预处理
特征提取和归一化。
- 应用程序: 转换输入数据,例如文本,以供机器学习算法使用。
- 算法: 预处理 特征提取

# 官网用户指南
1.有监督学习
2.无监督学习
3.模型选择与评估
4.检验
5.可视化
6.数据集转换
7.数据集加载实用程序
8.使用scikit-learn计算
# 【----------------------------】
# Python之(scikit-learn)机器学习
# 机器学习 定义
一、机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论 (opens new window)、凸分析 (opens new window)、算法复杂度 (opens new window)理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
简而言之,机器学习就是通过一系列变种的数据公式,通过大量的数据推导,得出的接近于满足数据点的一个公式(f(x) = w1x1 + w2x2^2 + w3x3^3 + ...),然后需要推测的新数据,通过该公式来得出预测的结果。
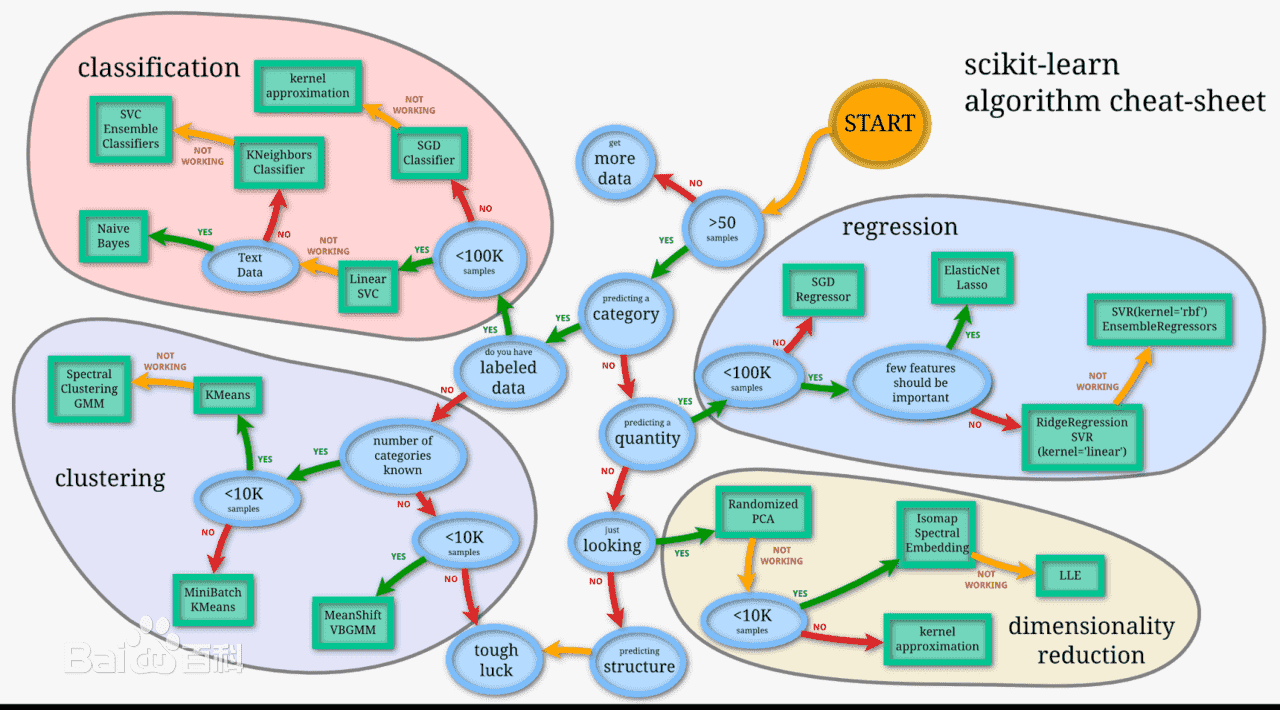
记住上面这个图,他是后续选择算法的规则,也是核心。
# scikit-learn 介绍
二、scikit-learn(简记sklearn),是用python实现的机器学习算法库。sklearn可以实现数据预处理、分类、回归、降维、模型选择等常用的机器学习算法。sklearn是基于**NumPy, (opens new window)matplotlib,\**SciPy\****而形成的。
scikit-learn的强大主要是它提供了很多算法库,以及数据处理的方式,学习scikit-learn很大程度上可以了解机器学习的实现、训练、预测过程。
# 机器学习的流程
三、在开始scikit-learn之前,我们先了解机器学习的流程:
# 1、原始数据:
原始数据可以是很多种形式(比如:图片,json,文本,table等),这些数据可以通过pandas (opens new window)来加载成一个二维数组的数据。也可以通过numpy (opens new window)的方式生成数据。
数据来源一般通过kaggle (opens new window)官方获取,地址:https://www.kaggle.com/
# 2、数据处理:
得到原始数据过后,我们需要对数据进行处理(比如:数据分割(训练集、测试集),构造特征(比如:时间(年份一样,月份、天构造新的特征)),删除特征(没有用的,但是存在影响的特征)等)
# 3、特征工程:
在数据进行处理过后,我们不能盲目的使用该数据(比如:文本数据,数值差异过大的数据),这个时候就要转换数据(转换器)。转换器:字典特征、文本特征、tf_idf(数据出现频次)、归一化、标准化、降维等,然后得出提取特征后的矩阵 (opens new window)数据。
# 4、算法模型:
(核心)主要分为监督学习 (opens new window)和无监督学习 (opens new window)。机器学习的核心就是算法模型。
监督学习:有特征值,目标值(有标准答案)。常有算法为分类算法(离散型(具体的分类标准))、回归算法(连续型(预测值))
无监督学习:只有特征值。常有算法为聚类。
模型:数据在训练集和测试集上面,反复的训练过后,会得出最接近满足所有数据点的公式也称为模型,这个也是后续用于其他业务数据用于分类或者预测的基础。
# 5、算法评估:
分类模型:一般是通过准确率、精准率、召回率、混淆矩阵、AUC来确认模型的准确度,回归模型:一般是通过均方误差的方式来确认准确度。
# 知识点介绍:
四、通过第三点的大致介绍,基本可以了解机器学习需要掌握的知识量还是不小的。特别是很多概念,需要自己去理解。下面主要是讲具体的过程和部分原理。(注意:算法是核心会放到最后讲)
(1)Python之原始数据-1 (opens new window)
(2)Python之数据处理-2 (opens new window)
(3)Python之特征工程-3 (opens new window)
(4)Python之算法评估-4 (opens new window)
(5)Python之算法模型-5.1 (opens new window)
(6)Python之网格搜索与检查验证-5.2 (opens new window)
(7)Python之模型的保存和加载-5.3 (opens new window)
# 源码
五、源码: https://github.com/lilin409546297/scikit_learn_demo
# 数据下载
六、数据下载地址:
k_near/train.csv:https://www.kaggle.com/c/facebook-v-predicting-check-ins/data
decision_tree/titanic.csv:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt
market/orders.csv、order_products__prior.csv、products.csv、market/aisles.csv:https://www.kaggle.com/psparks/instacart-market-basket-analysis
classify_regression/breast-cancer-wisconsin.data:https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/
# 参考文章
- https://www.cnblogs.com/ll409546297/p/11211997.html
- https://scikit-learn.org.cn/










