TIP
本文主要是介绍 DL4J-简单人脸识别案例 。
# 转载:如何用DL4J构建起一个人脸识别系统
# 一、概述
人脸识别本质上是一个求相似度的问题,相同的人脸映射到同一个空间,他们的距离比较近,这个距离的度量可以是余弦距离,也可以是欧几里得距离,或者其他的距离。下面有三个头像。



A B C
显然A和C是相同人脸,A和B是不同人脸,用数学怎么描述呢?假设有个距离函数d(x1,x2),那么 d(A,B) > d(A,C)。在真实的人脸识别应用中,函数d(x1,x2)小到一个什么范围才认定为同一张人脸呢?这个值和训练模型时的参数有关,这个将在下文中给出。值得注意的是,如果函数d为cosine,则值越大表示越相似。一个通用的人脸识别模型应该包含特征提取(也就是特征映射)和距离计算两个单元。
# 二、构造模型
那么有什么办法可以特征映射呢?对于图像的处理,卷积神经网络无疑是目前最优的办法。DeepLearning4J已经内置了训练好的VggFace模型,是基于vgg16训练的。vggFace的下载地址:https://dl4jdata.blob.core.windows.net/models/vgg16_dl4j_vggface_inference.v1.zip,这个地址是怎么获取到的呢?直接跟一下源码VGG16,pretrainedUrl方法里的DL4JResources.getURLString方法便有相关模型的下载地址,VGG19、ResNet50等等pretrained的模型下载地址,都可以这样找到。源码如下
public class VGG16 extends ZooModel {
@Builder.Default private long seed = 1234;
@Builder.Default private int[] inputShape = new int[] {3, 224, 224};
@Builder.Default private int numClasses = 0;
@Builder.Default private IUpdater updater = new Nesterovs();
@Builder.Default private CacheMode cacheMode = CacheMode.NONE;
@Builder.Default private WorkspaceMode workspaceMode = WorkspaceMode.ENABLED;
@Builder.Default private ConvolutionLayer.AlgoMode cudnnAlgoMode = ConvolutionLayer.AlgoMode.PREFER_FASTEST;
private VGG16() {}
@Override
public String pretrainedUrl(PretrainedType pretrainedType) {
if (pretrainedType == PretrainedType.IMAGENET)
return DL4JResources.getURLString("models/vgg16_dl4j_inference.zip");
else if (pretrainedType == PretrainedType.CIFAR10)
return DL4JResources.getURLString("models/vgg16_dl4j_cifar10_inference.v1.zip");
else if (pretrainedType == PretrainedType.VGGFACE)
return DL4JResources.getURLString("models/vgg16_dl4j_vggface_inference.v1.zip");
else
return null;
}
# vgg16的模型结构如下:
====================================================================================================
VertexName (VertexType) nIn,nOut TotalParams ParamsShape Vertex Inputs
====================================================================================================
input_1 (InputVertex) -,- - - -
conv1_1 (ConvolutionLayer) 3,64 1,792 W:{64,3,3,3}, b:{1,64} [input_1]
conv1_2 (ConvolutionLayer) 64,64 36,928 W:{64,64,3,3}, b:{1,64} [conv1_1]
pool1 (SubsamplingLayer) -,- 0 - [conv1_2]
conv2_1 (ConvolutionLayer) 64,128 73,856 W:{128,64,3,3}, b:{1,128} [pool1]
conv2_2 (ConvolutionLayer) 128,128 147,584 W:{128,128,3,3}, b:{1,128} [conv2_1]
pool2 (SubsamplingLayer) -,- 0 - [conv2_2]
conv3_1 (ConvolutionLayer) 128,256 295,168 W:{256,128,3,3}, b:{1,256} [pool2]
conv3_2 (ConvolutionLayer) 256,256 590,080 W:{256,256,3,3}, b:{1,256} [conv3_1]
conv3_3 (ConvolutionLayer) 256,256 590,080 W:{256,256,3,3}, b:{1,256} [conv3_2]
pool3 (SubsamplingLayer) -,- 0 - [conv3_3]
conv4_1 (ConvolutionLayer) 256,512 1,180,160 W:{512,256,3,3}, b:{1,512} [pool3]
conv4_2 (ConvolutionLayer) 512,512 2,359,808 W:{512,512,3,3}, b:{1,512} [conv4_1]
conv4_3 (ConvolutionLayer) 512,512 2,359,808 W:{512,512,3,3}, b:{1,512} [conv4_2]
pool4 (SubsamplingLayer) -,- 0 - [conv4_3]
conv5_1 (ConvolutionLayer) 512,512 2,359,808 W:{512,512,3,3}, b:{1,512} [pool4]
conv5_2 (ConvolutionLayer) 512,512 2,359,808 W:{512,512,3,3}, b:{1,512} [conv5_1]
conv5_3 (ConvolutionLayer) 512,512 2,359,808 W:{512,512,3,3}, b:{1,512} [conv5_2]
pool5 (SubsamplingLayer) -,- 0 - [conv5_3]
flatten (PreprocessorVertex) -,- - - [pool5]
fc6 (DenseLayer) 25088,4096 102,764,544 W:{25088,4096}, b:{1,4096} [flatten]
fc7 (DenseLayer) 4096,4096 16,781,312 W:{4096,4096}, b:{1,4096} [fc6]
fc8 (DenseLayer) 4096,2622 10,742,334 W:{4096,2622}, b:{1,2622} [fc7]
----------------------------------------------------------------------------------------------------
Total Parameters: 145,002,878
Trainable Parameters: 145,002,878
Frozen Parameters: 0
对于VggFace我们只需要前面的卷积层和池化层来提取特征,其他的全连接层可以丢弃掉,那么我们的模型可以设置成如下的样子。
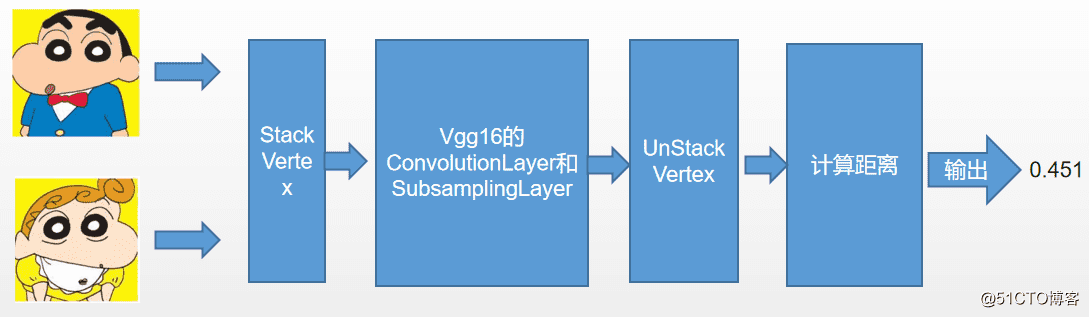
说明:这里用StackVertex和UnStackVertex的原因是,dl4j中默认情况下有都给输入时是把张量Merge在一起输入的,达不到多个输入共享权重的目的,所以这里先用StackVertex沿着第0维堆叠张量,共享卷积和池化提取特征,再用UnStackVertex拆开张量,给后面用于计算距离用。
接下来的问题是,dl4j中迁移学习api只能在模型尾部追加相关的结构,而现在我们的场景是把pretrained的模型的部分结构放在中间,怎么办呢?不着急,我们看看迁移学习API的源码,看DL4J是怎么封装的。在org.deeplearning4j.nn.transferlearning.TransferLearning的build方法中找到了蛛丝马迹。
public ComputationGraph build() {
initBuilderIfReq();
ComputationGraphConfiguration newConfig = editedConfigBuilder
.validateOutputLayerConfig(validateOutputLayerConfig == null ? true : validateOutputLayerConfig).build();
if (this.workspaceMode != null)
newConfig.setTrainingWorkspaceMode(workspaceMode);
ComputationGraph newGraph = new ComputationGraph(newConfig);
newGraph.init();
int[] topologicalOrder = newGraph.topologicalSortOrder();
org.deeplearning4j.nn.graph.vertex.GraphVertex[] vertices = newGraph.getVertices();
if (!editedVertices.isEmpty()) {
//set params from orig graph as necessary to new graph
for (int i = 0; i < topologicalOrder.length; i++) {
if (!vertices[topologicalOrder[i]].hasLayer())
continue;
org.deeplearning4j.nn.api.Layer layer = vertices[topologicalOrder[i]].getLayer();
String layerName = vertices[topologicalOrder[i]].getVertexName();
long range = layer.numParams();
if (range <= 0)
continue; //some layers have no params
if (editedVertices.contains(layerName))
continue; //keep the changed params
INDArray origParams = origGraph.getLayer(layerName).params();
layer.setParams(origParams.dup()); //copy over origGraph params
}
} else {
newGraph.setParams(origGraph.params());
}
原来是直接调用 layer.setParams方法,给每一个层set相关的参数即可。接下来,我们就有思路了,直接构造一个和vgg16一样的模型,把vgg16的参数set到新的模型里即可。其实本质上,DeepLearning被train之后,有用的就是参数而已,有了这些参数,我们就可以随心所欲的用这些模型了。废话不多说,我们直接上代码,构建我们目标模型
private static ComputationGraph buildModel() {
ComputationGraphConfiguration conf = new NeuralNetConfiguration.Builder().seed(123)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT).activation(Activation.RELU)
.graphBuilder().addInputs("input1", "input2").addVertex("stack", new StackVertex(), "input1", "input2")
.layer("conv1_1",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nIn(3).nOut(64)
.build(),
"stack")
.layer("conv1_2",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(64).build(),
"conv1_1")
.layer("pool1",
new SubsamplingLayer.Builder().poolingType(SubsamplingLayer.PoolingType.MAX).kernelSize(2, 2)
.stride(2, 2).build(),
"conv1_2")
// block 2
.layer("conv2_1",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(128).build(),
"pool1")
.layer("conv2_2",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(128).build(),
"conv2_1")
.layer("pool2",
new SubsamplingLayer.Builder().poolingType(SubsamplingLayer.PoolingType.MAX).kernelSize(2, 2)
.stride(2, 2).build(),
"conv2_2")
// block 3
.layer("conv3_1",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(256).build(),
"pool2")
.layer("conv3_2",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(256).build(),
"conv3_1")
.layer("conv3_3",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(256).build(),
"conv3_2")
.layer("pool3",
new SubsamplingLayer.Builder().poolingType(SubsamplingLayer.PoolingType.MAX).kernelSize(2, 2)
.stride(2, 2).build(),
"conv3_3")
// block 4
.layer("conv4_1",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(512).build(),
"pool3")
.layer("conv4_2",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(512).build(),
"conv4_1")
.layer("conv4_3",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(512).build(),
"conv4_2")
.layer("pool4",
new SubsamplingLayer.Builder().poolingType(SubsamplingLayer.PoolingType.MAX).kernelSize(2, 2)
.stride(2, 2).build(),
"conv4_3")
// block 5
.layer("conv5_1",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(512).build(),
"pool4")
.layer("conv5_2",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(512).build(),
"conv5_1")
.layer("conv5_3",
new ConvolutionLayer.Builder().kernelSize(3, 3).stride(1, 1).padding(1, 1).nOut(512).build(),
"conv5_2")
.layer("pool5",
new SubsamplingLayer.Builder().poolingType(SubsamplingLayer.PoolingType.MAX).kernelSize(2, 2)
.stride(2, 2).build(),
"conv5_3")
.addVertex("unStack1", new UnstackVertex(0, 2), "pool5")
.addVertex("unStack2", new UnstackVertex(1, 2), "pool5")
.addVertex("cosine", new CosineLambdaVertex(), "unStack1", "unStack2")
.addLayer("out", new LossLayer.Builder().build(), "cosine").setOutputs("out")
.setInputTypes(InputType.convolutionalFlat(224, 224, 3), InputType.convolutionalFlat(224, 224, 3))
.build();
ComputationGraph network = new ComputationGraph(conf);
network.init();
return network;
}
接下来读取VGG16的参数,set到我们的新模型里。为了代码方便,我们将LayerName设定的和vgg16里一样
String vggLayerNames = "conv1_1,conv1_2,conv2_1,conv2_2,conv3_1,conv3_2,conv3_3,conv4_1,conv4_2,conv4_3,conv5_1,conv5_2,conv5_3";
File vggfile = new File("F:/vgg16_dl4j_vggface_inference.v1.zip");
ComputationGraph vggFace =
ModelSerializer.restoreComputationGraph(vggfile);
ComputationGraph model = buildModel();
for (String name : vggLayerNames.split(",")) {
model.getLayer(name).setParams(vggFace.getLayer(name).params().dup());
}
特征提取层构造完毕,提取特征之后,我们要计算距离了,这里就需要用DL4J实现自定义层,DL4J提供的自动微分可以非常方便的实现自定义层,这里我们选择 SameDiffLambdaVertex,原因是这一层不需要任何参数,仅仅计算cosine即可,代码如下:
public class CosineLambdaVertex extends SameDiffLambdaVertex {
@Override
public SDVariable defineVertex(SameDiff sameDiff, VertexInputs inputs) {
SDVariable input1 = inputs.getInput(0);
SDVariable input2 = inputs.getInput(1);
return sameDiff.expandDims(sameDiff.math.cosineSimilarity(input1, input2, 1, 2, 3), 1);
}
@Override
public InputType getOutputType(int layerIndex, InputType... vertexInputs) throws InvalidInputTypeException {
return InputType.feedForward(1);
}
}
说明:计算cosine之后这里用expandDims将一维张量拓宽成二维,是为了在LFW数据集中验证模型的准确性。
DL4J也提供其他的自定层和自定义节点的实现,一共有如下五种:
- Layers: standard single input, single output layers defined using SameDiff. To implement, extend org.deeplearning4j.nn.conf.layers.samediff.SameDiffLayer
- Lambda layers: as above, but without any parameters. You only need to implement a single method for these! To implement, extend org.deeplearning4j.nn.conf.layers.samediff.SameDiffLambdaLayer
- Graph vertices: multiple inputs, single output layers usable only in ComputationGraph. To implement: extend org.deeplearning4j.nn.conf.layers.samediff.SameDiffVertex
- Lambda vertices: as above, but without any parameters. Again, you only need to implement a single method for these! To implement, extend org.deeplearning4j.nn.conf.layers.samediff.SameDiffLambdaVertex
- Output layers: An output layer, for calculating scores/losses. Used as the final layer in a network. To implement, extend org.deeplearning4j.nn.conf.layers.samediff.SameDiffOutputLayer
案例地址:https://github.com/eclipse/deeplearning4j-examples/tree/master/samediff-examples
说明文档:https://github.com/eclipse/deeplearning4j-examples/blob/master/samediff-examples/src/main/java/org/nd4j/examples/samediff/customizingdl4j/README.md
接下来,还有最后一个问题,输出层怎么定义?输出层不需要任何参数和计算,仅仅将cosine结果输出即可,dl4j中提供LossLayer天然满足这种结构,没有参数,且激活函数为恒等函数IDENTITY。那么到此为止模型构造完成,最终结构如下:
=========================================================================================================
VertexName (VertexType) nIn,nOut TotalParams ParamsShape Vertex Inputs
=========================================================================================================
input1 (InputVertex) -,- - - -
input2 (InputVertex) -,- - - -
stack (StackVertex) -,- - - [input1, input2]
conv1_1 (ConvolutionLayer) 3,64 1,792 W:{64,3,3,3}, b:{1,64} [stack]
conv1_2 (ConvolutionLayer) 64,64 36,928 W:{64,64,3,3}, b:{1,64} [conv1_1]
pool1 (SubsamplingLayer) -,- 0 - [conv1_2]
conv2_1 (ConvolutionLayer) 64,128 73,856 W:{128,64,3,3}, b:{1,128} [pool1]
conv2_2 (ConvolutionLayer) 128,128 147,584 W:{128,128,3,3}, b:{1,128} [conv2_1]
pool2 (SubsamplingLayer) -,- 0 - [conv2_2]
conv3_1 (ConvolutionLayer) 128,256 295,168 W:{256,128,3,3}, b:{1,256} [pool2]
conv3_2 (ConvolutionLayer) 256,256 590,080 W:{256,256,3,3}, b:{1,256} [conv3_1]
conv3_3 (ConvolutionLayer) 256,256 590,080 W:{256,256,3,3}, b:{1,256} [conv3_2]
pool3 (SubsamplingLayer) -,- 0 - [conv3_3]
conv4_1 (ConvolutionLayer) 256,512 1,180,160 W:{512,256,3,3}, b:{1,512} [pool3]
conv4_2 (ConvolutionLayer) 512,512 2,359,808 W:{512,512,3,3}, b:{1,512} [conv4_1]
conv4_3 (ConvolutionLayer) 512,512 2,359,808 W:{512,512,3,3}, b:{1,512} [conv4_2]
pool4 (SubsamplingLayer) -,- 0 - [conv4_3]
conv5_1 (ConvolutionLayer) 512,512 2,359,808 W:{512,512,3,3}, b:{1,512} [pool4]
conv5_2 (ConvolutionLayer) 512,512 2,359,808 W:{512,512,3,3}, b:{1,512} [conv5_1]
conv5_3 (ConvolutionLayer) 512,512 2,359,808 W:{512,512,3,3}, b:{1,512} [conv5_2]
pool5 (SubsamplingLayer) -,- 0 - [conv5_3]
unStack1 (UnstackVertex) -,- - - [pool5]
unStack2 (UnstackVertex) -,- - - [pool5]
cosine (SameDiffGraphVertex) -,- - - [unStack1, unStack2]
out (LossLayer) -,- 0 - [cosine]
---------------------------------------------------------------------------------------------------------
Total Parameters: 14,714,688
Trainable Parameters: 14,714,688
Frozen Parameters: 0
=========================================================================================================
# 三、在LFW上验证模型准确率
LFW数据下载地址:http://vis-www.cs.umass.edu/lfw/,我下载之后放在了F:\facerecognition目录下。
构造测试集,分别构造正例和负例,将相同的人脸放一堆,不同的人脸放一堆,代码如下:
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.Random;
public class DataTools {
private static final String PARENT_PATH = "F:/facerecognition";
public static void main(String[] args) throws IOException {
File file = new File(PARENT_PATH + "/lfw");
List<File> list = Arrays.asList(file.listFiles());
for (int i = 0; i < list.size(); i++) {
String name = list.get(i).getName();
File[] faceFileArray = list.get(i).listFiles();
if (null == faceFileArray) {
continue;
}
//构造正例
if (faceFileArray.length > 1) {
String positiveFilePath = PARENT_PATH + "/pairs/1/" + name;
File positiveFileDir = new File(positiveFilePath);
if (positiveFileDir.exists()) {
positiveFileDir.delete();
}
positiveFileDir.mkdir();
FileUtils.copyFile(faceFileArray[0], new File(positiveFilePath + "/" + faceFileArray[0].getName()));
FileUtils.copyFile(faceFileArray[1], new File(positiveFilePath + "/" + faceFileArray[1].getName()));
}
//构造负例
String negativeFilePath = PARENT_PATH + "/pairs/0/" + name;
File negativeFileDir = new File(negativeFilePath);
if (negativeFileDir.exists()) {
negativeFileDir.delete();
}
negativeFileDir.mkdir();
FileUtils.copyFile(faceFileArray[0], new File(negativeFilePath + "/" + faceFileArray[0].getName()));
File[] differentFaceArray = list.get(randomInt(list.size(), i)).listFiles();
int differentFaceIndex = randomInt(differentFaceArray.length, -1);
FileUtils.copyFile(differentFaceArray[differentFaceIndex], new File(negativeFilePath + "/" + differentFaceArray[differentFaceIndex].getName()));
}
}
public static int randomInt(int max, int target) {
Random random = new Random();
while (true) {
int result = random.nextInt(max);
if (result != target) {
return result;
}
}
}
}
测试集构造完成之后,构造迭代器,迭代器中读取图片用了NativeImageLoader,在《如何利用deeplearning4j中datavec对图像进行处理》有相关介绍。
public class DataSetForEvaluation implements MultiDataSetIterator {
private List<FacePair> facePairList;
private int batchSize;
private int totalBatches;
private NativeImageLoader imageLoader;
private int currentBatch = 0;
public DataSetForEvaluation(List<FacePair> facePairList, int batchSize) {
this.facePairList = facePairList;
this.batchSize = batchSize;
this.totalBatches = (int) Math.ceil((double) facePairList.size() / batchSize);
this.imageLoader = new NativeImageLoader(224, 224, 3, new ResizeImageTransform(224, 224));
}
@Override
public boolean hasNext() {
return currentBatch < totalBatches;
}
@Override
public MultiDataSet next() {
return next(batchSize);
}
@Override
public MultiDataSet next(int num) {
int i = currentBatch * batchSize;
int currentBatchSize = Math.min(batchSize, facePairList.size() - i);
INDArray input1 = Nd4j.zeros(currentBatchSize, 3,224,224);
INDArray input2 = Nd4j.zeros(currentBatchSize, 3,224,224);
INDArray label = Nd4j.zeros(currentBatchSize, 1);
for (int j = 0; j < currentBatchSize; j++) {
try {
input1.put(new INDArrayIndex[]{NDArrayIndex.point(j),NDArrayIndex.all(),NDArrayIndex.all(),NDArrayIndex.all()}, imageLoader.asMatrix(facePairList.get(i).getList().get(0)).div(255));
input2.put(new INDArrayIndex[]{NDArrayIndex.point(j),NDArrayIndex.all(),NDArrayIndex.all(),NDArrayIndex.all()},imageLoader.asMatrix(facePairList.get(i).getList().get(1)).div(255));
} catch (Exception e) {
e.printStackTrace();
}
label.putScalar((long) j, 0, facePairList.get(i).getLabel());
++i;
}
System.out.println(currentBatch);
++currentBatch;
return new org.nd4j.linalg.dataset.MultiDataSet(new INDArray[] { input1, input2},
new INDArray[] { label });
}
@Override
public void setPreProcessor(MultiDataSetPreProcessor preProcessor) {
}
@Override
public MultiDataSetPreProcessor getPreProcessor() {
return null;
}
@Override
public boolean resetSupported() {
return true;
}
@Override
public boolean asyncSupported() {
return false;
}
@Override
public void reset() {
currentBatch = 0;
}
}
接下来可以评估模型的性能了,准确率和精确率还凑合,但F1值有点低。
========================Evaluation Metrics========================
# of classes: 2
Accuracy: 0.8973
Precision: 0.9119
Recall: 0.6042
F1 Score: 0.7268
Precision, recall & F1: reported for positive class (class 1 - "1") only
=========================Confusion Matrix=========================
0 1
-----------
5651 98 | 0 = 0
665 1015 | 1 = 1
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times
==================================================================1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
# 四、用SpringBoot将模型封装成服务
模型保存之后,就是一堆死参数,怎么变成线上的服务呢?人脸识别服务分为两种1:1和1:N
# 1、1:1应用
典型的1:1应用如手机的人脸识别解锁,钉钉的人脸识别考勤,这种应用比较简单,仅仅只需要张三是张三即可,运算量很小。很容易实现
# 2、1:N应用
典型的1:N应用如公安机关的人脸找人,在不知道目标人脸身份的前提下,从海量人脸库中找到目标人脸是谁。当人脸库中数据量巨大的时候,计算是一个很大的问题。
如果不要求结构可以实时出来,可以离线用Hadoop MapReduce或者Spark来计算一把,我们需要做的工作仅仅是封装一个Hive UDF函数、或者MapReduce jar,再或者是Spark RDD编程即可。
但对于要求计算结果实时性,这个问题不能转化为一个索引问题,所以需要设计一种计算框架,可以分布式的解决全局Max或者全局Top的问题,大致结构如下:
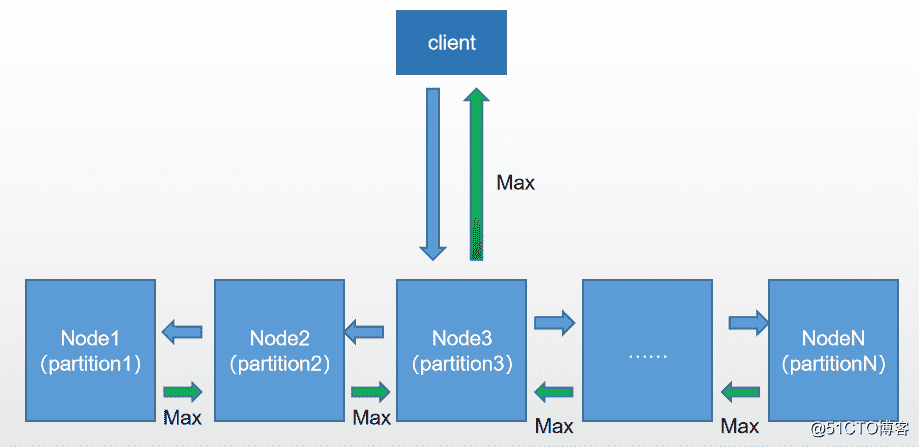
蓝色箭头表示请求留向,绿色箭头表示计算结果返回,图中描述了一个客户端请求打到了节点Node3上,由Node3转发请求到其他Node,并行计算。当然如果各个Node内存够大,可以将整个人脸库的张量都预热到内存常驻,加快计算速度。
当然,本篇博客中并没有实现并行计算框架,只实现了用springboot将模型包装成服务。运行FaceRecognitionApplication,访问http://localhost:8080/index,服务效果如下:

本篇博客的所有代码:https://gitee.com/lxkm/dl4j-demo/tree/master/face-recognition
# 五、总结
本篇博客的主要意图是介绍如何把DL4J用于实战,包括pretrained模型参数的获取、自定义层的实现,自定义迭代器的实现,用springboot包装层服务等等。
当然一个人脸识别系统只有一个图片embedding和求张量距离是不够的,还应该包括人脸矫正、抵御AI attack(后面的博客也会介绍如何用DL4J进行 FGSM 攻击)、人脸关键部位特征提取等等很多精细化的工作要做。当然要把人脸识别做成一个通用SAAS服务,也是有很多工作要做。
要训练一个好的人脸识别模型,需要多种loss function的配合,如可以先用SoftMax做分类,再用Center Loss、Triple Loss做微调,后续的博客中将介绍如何用DL4J实现Triple Loss( 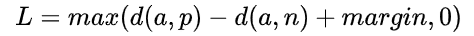 ),来训练人脸识别模型。
),来训练人脸识别模型。
# 参考文章
- https://blog.51cto.com/u_15162069/2901011










