TIP
本文主要是介绍 Flink-电商用户行为项目介绍 。
# 转载:基于flink的电商用户行为数据分析【1】| 项目整体介绍
本文已收录github:https://github.com/BigDataScholar/TheKingOfBigData,里面有大数据高频考点,Java一线大厂面试题资源,上百本免费电子书籍,作者亲绘大数据生态圈思维导图…持续更新,欢迎star!
# 前言
愉悦的一周又要开始了,本周菌哥打算用几期文章为大家分享一个之前在B站自学的一个项目——基于flink的电商用户行为数据分析。本期我们先对项目整体功能和模块做一个介绍。
正式介绍项目整体之前,我们来探讨一下批处理和流处理技术。
# 批处理 VS 流处理
批处理和流处理代表了现在大数据处理领域两种完全不同的数据处理方式。
下面两组分别列出的分别是批处理和流处理的"代表作"。

左边Hadoop和Spark是“批处理”的代表作,其中Spark可以被认为是批处理的“巅峰之作”,已经非常成熟,并且社区也非常广泛,应用的领域也很多。
右边Storm和Flink是“流处理”的代表作,其中Storm是流处理的“先锋”,但它本身有很多问题。Storm是首次真正意义上实现“流处理”,来一个数据就处理一个。但它随之带来的一个问题就是,在大数据应用场景下,吞吐量不够。另外如果数据出现乱序,Storm也处理不了。而Flink的引入,在Storm的基础上,完美的解决了着这两个问题。Flink可以说,是目前“流处理”的一个高峰!
那具体“批处理”和“流处理”有哪些特点,我们来做一个对比:
# 批处理
- 批处理主要操作大容量静态数据集,并在计算过程完成后返回结果。可以认为,处理的是用一个固定时间间隔分组的数据点集合。批处理模式中使用的数据集通常符合下列特征:
– 有界:批处理数据集代表数据的有限集合
– 持久:数据通常始终存储在某种类型的持久存储位置中
– 大量:批处理操作通常是处理极为海量数据集的唯一方法
# 流处理
- 流处理可以对随时进入系统的数据进行计算。流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作。流处理中的数据集是“无边界”的,这就产生了几个重要的影响:
– 可以处理几乎无限量的数据,但同一时间只能处理一条数据,不同记录间只维持最少量的状态。
– 处理工作是基于事件的,除非明确停止否则没有“尽头”。
– 处理结果立刻可用,并会随着新数据的抵达继续更新。
很好,回顾了批处理和流处理的区别之后,我们直接进入项目的整体介绍!
# 项目整体介绍
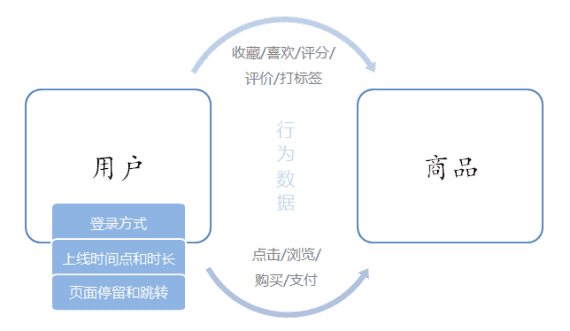
电商平台中的用户行为**频繁且较复杂**,系统上线运行一段时间后,可以收集到大量的用户行为数据,进而利用**大数据技术进行深入挖掘和分析,得到感兴趣的商业指标并增强对风险的控制**。
电商用户行为数据多样,整体可以分为用户行为习惯数据和业务行为数据两大类。用户的行为习惯数据包括了用户的登录方式、上线的时间点及时长、点击和浏览页面、页面停留时间以及页面跳转等等,我们可以从中进行流量统计和热门商品的统计,也可以深入挖掘用户的特征;这些数据往往可以从web服务器日志中直接读取到。而业务行为数据就是用户在电商平台中针对每个业务(通常是某个具体商品)所作的操作,我们一般会在业务系统中相应的位置埋点,然后收集日志进行分析。业务行为数据又可以简单分为两类:一类是能够明显地表现出用户兴趣的行为,比如对商品的收藏、喜欢、评分和评价,我们可以从中对数据进行深入分析,得到用户画像,进而对用户给出个性化的推荐商品列表,这个过程往往会用到机器学习相关的算法;另一类则是常规的业务操作,但需要着重关注一些异常状况以做好风控,比如登录和订单支付。
# 项目主要模块
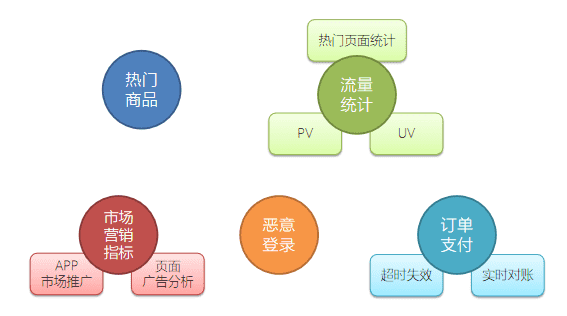
基于对电商用户行为数据的基本分类,我们可以发现主要有以下三个分析方向:
1、热门统计
利用用户的点击浏览行为,进行流量统计、近期热门商品统计等。
2、偏好统计
利用用户的偏好行为,比如收藏、喜欢、评分等,进行用户画像分析,给出个性化的商品推荐列表。
3、风险控制
利用用户的常规业务行为,比如登录、下单、支付等,分析数据,对异常情况进行报警提示。
总结:
- 统计分析 – 点击、浏览 – 热门商品、近期热门商品、分类热门商品、流量统计
- 统计分析 – 收藏、喜欢、评分、打标签 – 用户画像,推荐列表(结合特征工程和机器学习算法)
- 风险控制 – 下订单、支付、登录 – 刷单监控,订单失效监控,恶意登录(短时间内频繁登录失败)监控
大的方面,我们可以将其分为实时统计分析和业务流程及风险控制领域

但本项目限于数据,我们只实现热门统计和风险控制中的部分内容,将包括以下四大模块:实时热门商品统计、实时流量统计、恶意登录监控和订单支付失效监控。

项目模块设计,可以参考这张图:
由于对实时性要求较高,我们会用flink作为数据处理的框架。在项目中,我们将综合运用flink的各种API,基于EventTime去处理基本的业务需求,并且灵活地使用底层的processFunction,基于状态编程和CEP去处理更加复杂的情形。
# 数据源解析
我们准备了一份淘宝用户行为数据集,保存为csv文件。本数据集包含了淘宝上某一天随机一百万用户的所有行为(包括点击、购买、收藏、喜欢)。数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| userId | Long | 加密后的用户ID |
| itemId | Long | 加密后的商品ID |
| categoryId | Int | 加密后的商品所属类别ID |
| behavior | String | 用户行为类型,包括(‘pv’, ‘’buy, ‘cart’, ‘fav’) |
| timestamp | Long | 行为发生的时间戳,单位秒 |
另外,我们还可以拿到web服务器的日志数据,这里以apache服务器的一份log为例,每一行日志记录了访问者的IP、userId、访问时间、访问方法以及访问的url,具体描述如下:
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| ip | String | 访问的 IP |
| userId | Long | 访问的 user ID |
| eventTime | Long | 访问时间 |
| method | String | 访问方法 GET/POST/PUT/DELETE |
| url | String | 访问的 url |
由于行为数据有限,在实时热门商品统计模块中可以使用UserBehavior数据集,而对于恶意登录监控和订单支付失效监控,我们只以示例数据来做演示。
# 小结
本期内容为大家回顾了关于批处理和流处理的特性及“代表作”分析,然后对于项目整体和主要模块做了一个说明。至此,基于flink的电商用户行为数据分析【1】| 项目整体介绍的内容就到这里,从下一期开始,我们就要正式步入实际需求,去完成功能模块的开发。
# 参考文章
- https://alice.blog.csdn.net/article/details/109959876










