TIP
本文主要是介绍 Flink-ClickHouse结合案例 。
# 基于 Flink+ClickHouse 打造轻量级点击流实时数仓
Flink 和 ClickHouse 分别是实时计算和(近实时)OLAP 领域的翘楚,也是近些年非常火爆的开源框架,很多大厂都在将两者结合使用来构建各种用途的实时平台,效果很好。关于两者的优点就不再赘述,本文来简单介绍笔者团队在点击流实时数仓方面的一点实践经验。
# 点击流及其维度建模
所谓点击流(click stream),就是指用户访问网站、App 等 Web 前端时在后端留下的轨迹数据,也是流量分析(traffic analysis)和用户行为分析(user behavior analysis)的基础。点击流数据一般以访问日志和埋点日志的形式存储,其特点是量大、维度丰富。以我们一个中等体量的普通电商平台为例,每天产生约 200GB 左右、数十亿条的原始日志,埋点事件 100+ 个,涉及 50+ 个维度。
按照 Kimball 的维度建模理论,点击流数仓遵循典型的星形模型,简图如下。
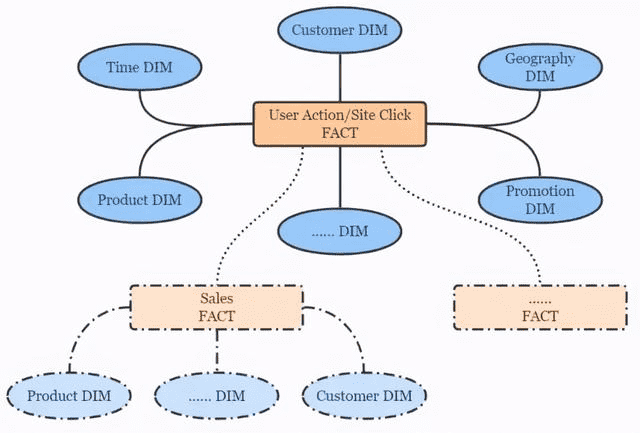
# 点击流数仓分层设计
点击流实时数仓的分层设计仍然可以借鉴传统数仓的方案,以扁平为上策,尽量减少数据传输中途的延迟。简图如下。
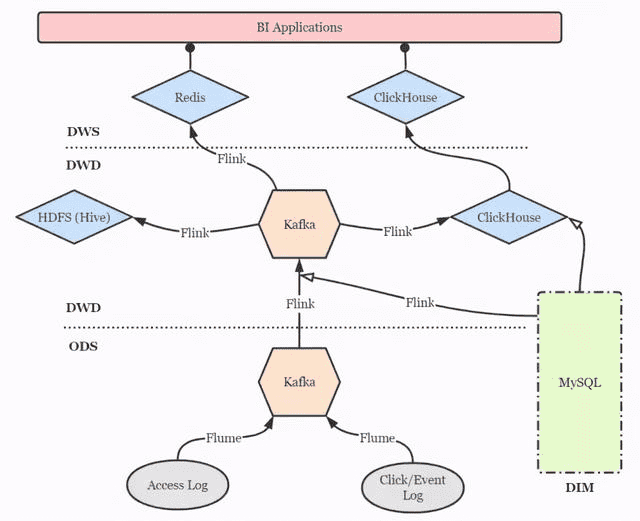
- DIM 层:维度层,MySQL 镜像库,存储所有维度数据。
- ODS 层:贴源层,原始数据由 Flume 直接进入 Kafka 的对应 topic。
- DWD 层:明细层,通过 Flink 将 Kafka 中数据进行必要的 ETL 与实时维度 join 操作,形成规范的明细数据,并写回 Kafka 以便下游与其他业务使用。再通过 Flink 将明细数据分别写入 ClickHouse 和 Hive 打成大宽表,前者作为查询与分析的核心,后者作为备份和数据质量保证(对数、补数等)。
- DWS 层:服务层,部分指标通过 Flink 实时汇总至 Redis,供大屏类业务使用。更多的指标则通过 ClickHouse 物化视图等机制周期性汇总,形成报表与页面热力图。特别地,部分明细数据也在此层开放,方便高级 BI 人员进行漏斗、留存、用户路径等灵活的 ad-hoc 查询,这些也是 ClickHouse 远超过其他 OLAP 引擎的强大之处。
# 要点与注意事项
Flink 实时维度关联
Flink 框架的异步 I/O 机制为用户在流式作业中访问外部存储提供了很大的便利。针对我们的情况,有以下三点需要注意:
- 使用异步 MySQL 客户端,如 Vert.x MySQL Client。
- AsyncFunction 内添加内存缓存(如 Guava Cache、Caffeine 等),并设定合理的缓存驱逐机制,避免频繁请求 MySQL 库。
- 实时维度关联仅适用于缓慢变化维度,如地理位置信息、商品及分类信息等。快速变化维度(如用户信息)则不太适合打进宽表,我们采用 MySQL 表引擎将快变维度表直接映射到 ClickHouse 中,而 ClickHouse 支持异构查询,也能够支撑规模较小的维表 join 场景。未来则考虑使用 MaterializedMySQL 引擎(当前仍未正式发布)将部分维度表通过 binlog 镜像到 ClickHouse。
Flink-ClickHouse Sink 设计
可以通过 JDBC(flink-connector-jdbc)方式来直接写入 ClickHouse,但灵活性欠佳。好在 clickhouse-jdbc 项目提供了适配 ClickHouse 集群的 BalancedClickhouseDataSource 组件,我们基于它设计了 Flink-ClickHouse Sink,要点有三:
- 写入本地表,而非分布式表,老生常谈了。
- 按数据批次大小以及批次间隔两个条件控制写入频率,在 part merge 压力和数据实时性两方面取得平衡。目前我们采用 10000 条的批次大小与 15 秒的间隔,只要满足其一则触发写入。
- BalancedClickhouseDataSource 通过随机路由保证了各 ClickHouse 实例的负载均衡,但是只是通过周期性 ping 来探活,并屏蔽掉当前不能访问的实例,而没有故障转移——亦即一旦试图写入已经失败的节点,就会丢失数据。为此我们设计了重试机制,重试次数和间隔均可配置,如果当重试机会耗尽后仍然无法成功写入,就将该批次数据转存至配置好的路径下,并报警要求及时检查与回填。
当前我们仅实现了 DataStream API 风格的 Flink-ClickHouse Sink,随着 Flink 作业 SQL 化的大潮,在未来还计划实现 SQL 风格的 ClickHouse Sink,打磨健壮后会适时回馈给社区。另外,除了随机路由,我们也计划加入轮询和 sharding key hash 等更灵活的路由方式。
还有一点就是,ClickHouse 并不支持事务,所以也不必费心考虑 2PC Sink 等保证 exactly once 语义的操作。如果 Flink 到 ClickHouse 的链路出现问题导致作业重启,作业会直接从最新的位点(即 Kafka 的 latest offset)开始消费,丢失的数据再经由 Hive 进行回填即可。
ClickHouse 数据重平衡
ClickHouse 集群扩容之后,数据的重平衡(reshard)是一件麻烦事,因为不存在类似 HDFS Balancer 这种开箱即用的工具。一种比较简单粗暴的思路是修改 ClickHouse 配置文件中的 shard weight,使新加入的 shard 多写入数据,直到所有节点近似平衡之后再调整回来。但是这会造成明显的热点问题,并且仅对直接写入分布式表才有效,并不可取。
因此,我们采用了一种比较曲折的方法:将原表重命名,在所有节点上建立与原表 schema 相同的新表,将实时数据写入新表,同时用 clickhouse-copier 工具将历史数据整体迁移到新表上来,再删除原表。当然在迁移期间,被重平衡的表是无法提供服务的,仍然不那么优雅。如果大佬们有更好的方案,欢迎交流。
# 【----------------------------】
# Flink实时写入clickhouse
# 代码案例Scala
package com.otis.clickhouse
import java.util
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessAllWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.triggers.{Trigger, TriggerResult}
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala._
import org.apache.flink.types.Row
import org.apache.flink.util.Collector
object FlinkJob3 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val settings = EnvironmentSettings.newInstance.useBlinkPlanner.inStreamingMode.build
val tableEnv = StreamTableEnvironment.create(env, settings)
val datagen =
"""
|create table datagen(
|name string,
|address string,
|age int
|)with(
|'connector'='datagen',
|'rows-per-second'='5'
|)
|""".stripMargin
tableEnv.executeSql(datagen)
val table = tableEnv.sqlQuery("select name,address,abs(age) from datagen")
val stream = tableEnv.toAppendStream[Row](table)
// flink有timeWindow和countWindow 都不满足需求
// 我既想按照一定时间聚合,又想如果条数达到batchSize就触发计算,只能定义触发器
// todo 目前问题是,在这个时间窗口内达到了maxcount计算了一次,触发计算后到窗口关闭的这段时间,有一批数据,0<数据量< maxcount,这一批数据会在时间窗口到达时触发计算
val stream2: DataStream[util.List[Row]] = stream.timeWindowAll(Time.seconds(5))
.trigger(new MyCountTrigger(20))
.process(new MyPWFunction)
val sql = "INSERT INTO user2 (name, address, age) VALUES (?,?,?)"
val tableColums = Array("name", "address", "age")
val types = Array("string", "string", "int")
stream2.print()
stream2.addSink(new MyClickHouseSink3(sql, tableColums, types))
env.execute("clickhouse sink test")
}
//触发器触发或者到时间后,把所有的结果收集到了这里,在这里计算
class MyPWFunction extends ProcessAllWindowFunction[Row, util.List[Row], TimeWindow] {
override def process(context: Context, elements: Iterable[Row], out: Collector[util.List[Row]]): Unit = {
val list = new util.ArrayList[Row]
elements.foreach(x => list.add(x))
out.collect(list)
}
}
class MyCountTrigger(maxCount: Int) extends Trigger[Row, TimeWindow] {
private lazy val count: ValueStateDescriptor[Int] = new ValueStateDescriptor[Int]("counter", classOf[Int])
override def onElement(element: Row, timestamp: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = {
val cnt_state = ctx.getPartitionedState(count)
val cnt = cnt_state.value()
cnt_state.update(cnt + 1)
if ((cnt + 1) >= maxCount) {
cnt_state.clear()
TriggerResult.FIRE_AND_PURGE
} else {
TriggerResult.CONTINUE
}
}
override def onProcessingTime(time: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = TriggerResult.FIRE_AND_PURGE
override def onEventTime(time: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = TriggerResult.CONTINUE
override def clear(window: TimeWindow, ctx: Trigger.TriggerContext): Unit = {
ctx.getPartitionedState(count).clear()
TriggerResult.PURGE
}
}
}
package com.otis.clickhouse;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.types.Row;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.util.List;
public class MyClickHouseSink3 extends RichSinkFunction<List<Row>> {
Connection connection = null;
String sql;
//Row 的字段和类型
private String[] tableColums;
private String[] types;
public MyClickHouseSink3(String sql, String[] tableColums, String[] types) {
this.sql = sql;
this.tableColums = tableColums;
this.types = types;
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
connection = ClickHouseUtil.getConnection("10.1.30.10", 8123, "qinghua");
}
@Override
public void close() throws Exception {
super.close();
connection.close();
}
@Override
public void invoke(List<Row> value, Context context) throws Exception {
PreparedStatement preparedStatement = connection.prepareStatement(sql);
for (Row e : value) {
int length = tableColums.length;
for (int i = 0; i < length; i++) {
String type = types[i];
if (e.getField(i) != null) {
switch (type) {
case "string":
preparedStatement.setString(i + 1, (String) e.getField(i));
break;
case "int":
preparedStatement.setInt(i + 1, (int) e.getField(i));
break;
default:
break;
}
} else {
preparedStatement.setObject(i + 1, null);
}
}
preparedStatement.addBatch();
}
long startTime = System.currentTimeMillis();
int[] ints = preparedStatement.executeBatch();
connection.commit();
long endTime = System.currentTimeMillis();
System.out.println("批量插入完毕用时:" + (endTime - startTime) + " -- 插入数据 = " + ints.length);
}
}
标签: clickhouse (opens new window), flink (opens new window)
# 【----------------------------】
# Flink自定义ClickHouseSink--数据写入ClickHouse
# 简介
遇到需要将Kafka数据写入ClickHouse的场景,本文将介绍如何使用Flink JDBC Connector将数据写入ClickHouse
# Flink JDBC Connector
Flink JDBC源码:
/**
* Default JDBC dialects.
*/
public final class JdbcDialects {
private static final List<JdbcDialect> DIALECTS = Arrays.asList(
new DerbyDialect(),
new MySQLDialect(),
new PostgresDialect(),
new ClickHouseDialect()
);
包含三种Connector,但是不包含ClickHouse的连接方式
现在通过自定义实现ClickHouseSink
# 一、下载Flink源码,添加ClickHOuseDialect文件
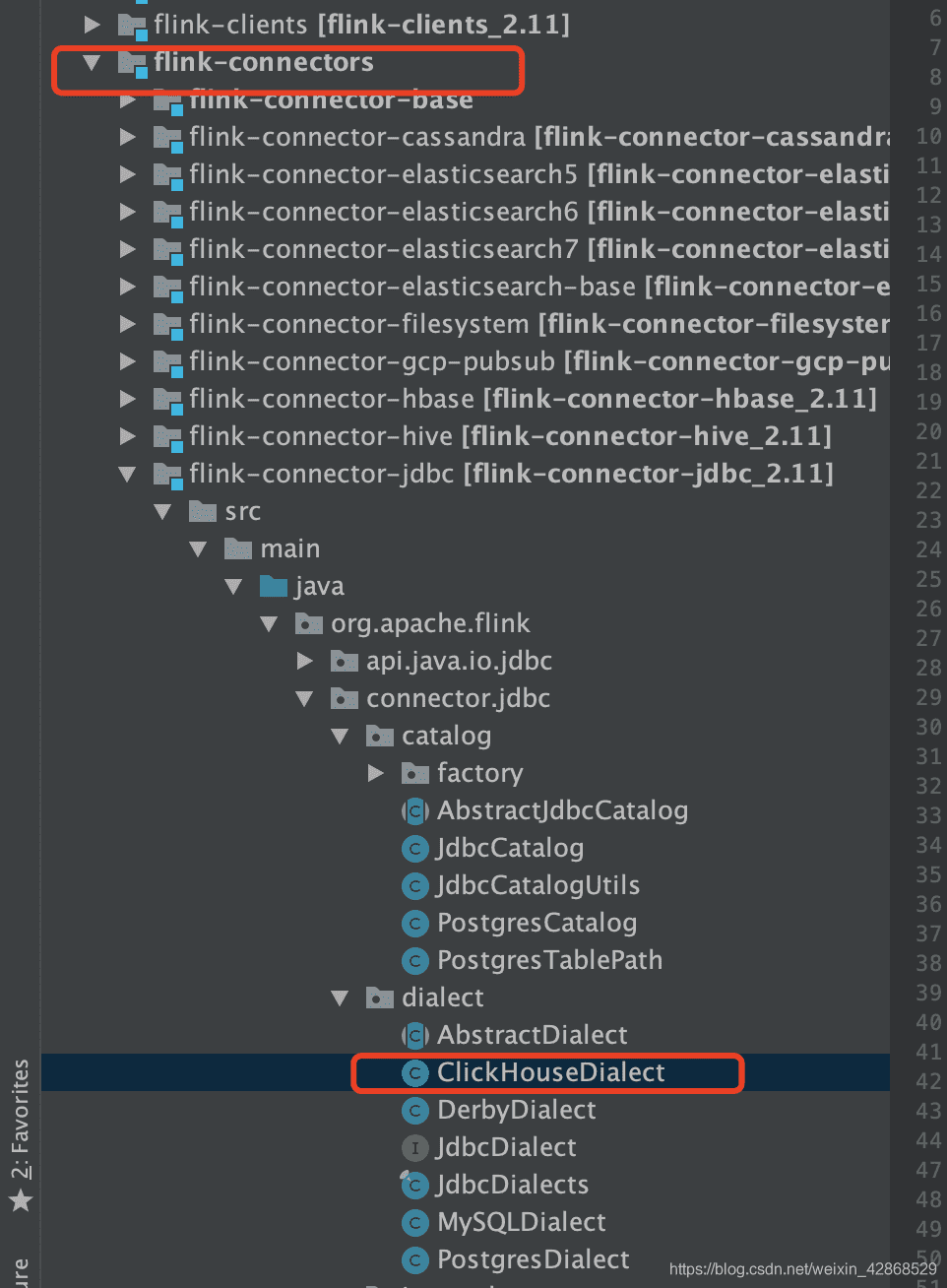
以下是ClickHOuseDialect文件里面的代码
备注:因为Clickhouse不支持删除操作,所以这个文件内的getDeleteStatement、getUpdateStatement方法都默认调的getInsertIntoStatement方法,即插入操作,有需求的也可以把删除和更新操作都实现了(有一个思路是给数据做一个标志字段,插入是1,删除是-1,更新是先-1,在1)
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.connector.jdbc.dialect;
import org.apache.flink.connector.jdbc.internal.converter.ClickHouseRowConverter;
import org.apache.flink.connector.jdbc.internal.converter.JdbcRowConverter;
import org.apache.flink.table.types.logical.LogicalTypeRoot;
import org.apache.flink.table.types.logical.RowType;
import java.util.Arrays;
import java.util.List;
import java.util.Optional;
/**
* JDBC dialect for ClickHouse.
*/
public class ClickHouseDialect extends AbstractDialect {
private static final long serialVersionUID = 1L;
@Override
public String dialectName() {
return "ClickHouse";
}
@Override
public boolean canHandle(String url) {
return url.startsWith("jdbc:clickhouse:");
}
@Override
public JdbcRowConverter getRowConverter(RowType rowType) {
return new ClickHouseRowConverter(rowType);
}
@Override
public Optional<String> defaultDriverName() {
return Optional.of("ru.yandex.clickhouse.ClickHouseDriver");
}
@Override
public String quoteIdentifier(String identifier) {
return "`" + identifier + "`";
}
@Override
public Optional<String> getUpsertStatement(String tableName, String[] fieldNames, String[] uniqueKeyFields) {
return Optional.of(getInsertIntoStatement(tableName, fieldNames));
}
@Override
public String getRowExistsStatement(String tableName, String[] conditionFields) {
return null;
}
// @Override
// public String getInsertIntoStatement(String tableName, String[] fieldNames) {
//
// }
@Override
public String getUpdateStatement(String tableName, String[] fieldNames, String[] conditionFields) {
return getInsertIntoStatement(tableName, fieldNames);
}
@Override
public String getDeleteStatement(String tableName, String[] fieldNames) {
return getInsertIntoStatement(tableName, fieldNames);
}
@Override
public String getSelectFromStatement(String tableName, String[] selectFields, String[] conditionFields) {
return null;
}
@Override
public int maxDecimalPrecision() {
return 0;
}
@Override
public int minDecimalPrecision() {
return 0;
}
@Override
public int maxTimestampPrecision() {
return 0;
}
@Override
public int minTimestampPrecision() {
return 0;
}
@Override
public List<LogicalTypeRoot> unsupportedTypes() {
// The data types used in Mysql are list at:
// https://dev.mysql.com/doc/refman/8.0/en/data-types.html
// TODO: We can't convert BINARY data type to
// PrimitiveArrayTypeInfo.BYTE_PRIMITIVE_ARRAY_TYPE_INFO in LegacyTypeInfoDataTypeConverter.
return Arrays.asList(
LogicalTypeRoot.BINARY,
LogicalTypeRoot.TIMESTAMP_WITH_LOCAL_TIME_ZONE,
LogicalTypeRoot.TIMESTAMP_WITH_TIME_ZONE,
LogicalTypeRoot.INTERVAL_YEAR_MONTH,
LogicalTypeRoot.INTERVAL_DAY_TIME,
LogicalTypeRoot.ARRAY,
LogicalTypeRoot.MULTISET,
LogicalTypeRoot.MAP,
LogicalTypeRoot.ROW,
LogicalTypeRoot.DISTINCT_TYPE,
LogicalTypeRoot.STRUCTURED_TYPE,
LogicalTypeRoot.NULL,
LogicalTypeRoot.RAW,
LogicalTypeRoot.SYMBOL,
LogicalTypeRoot.UNRESOLVED
);
}
}
完了把ClickHouseDialect方法加到JdbcDialects下
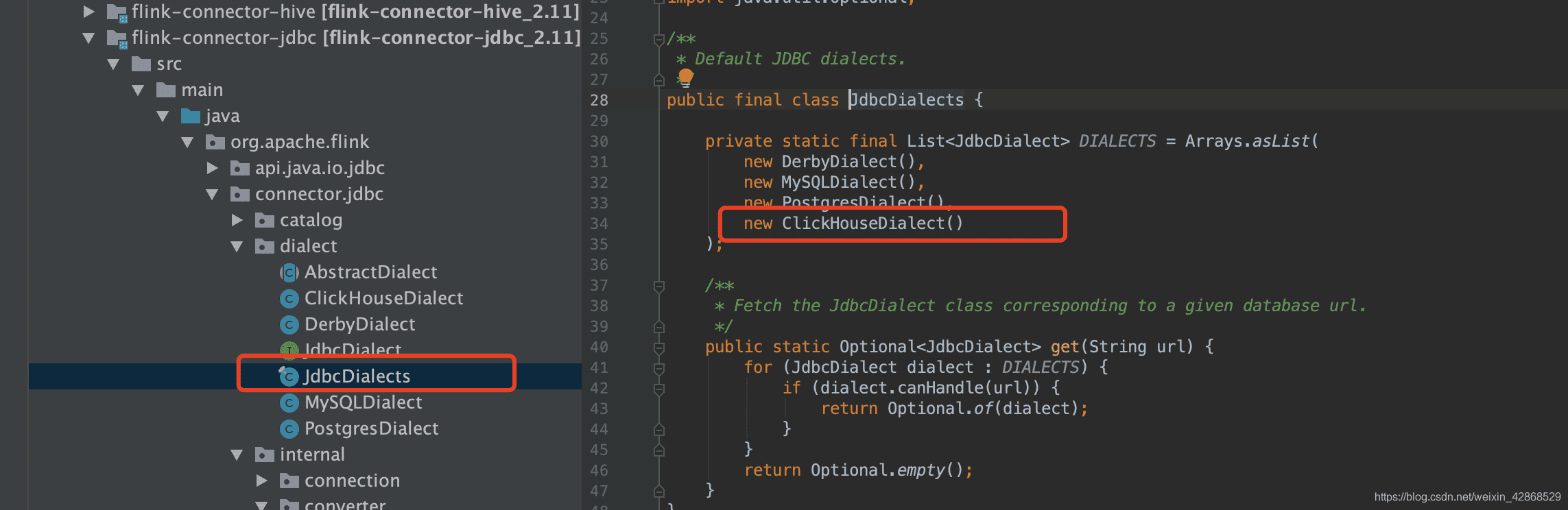
# 二、添加ClickHouseRowConverter
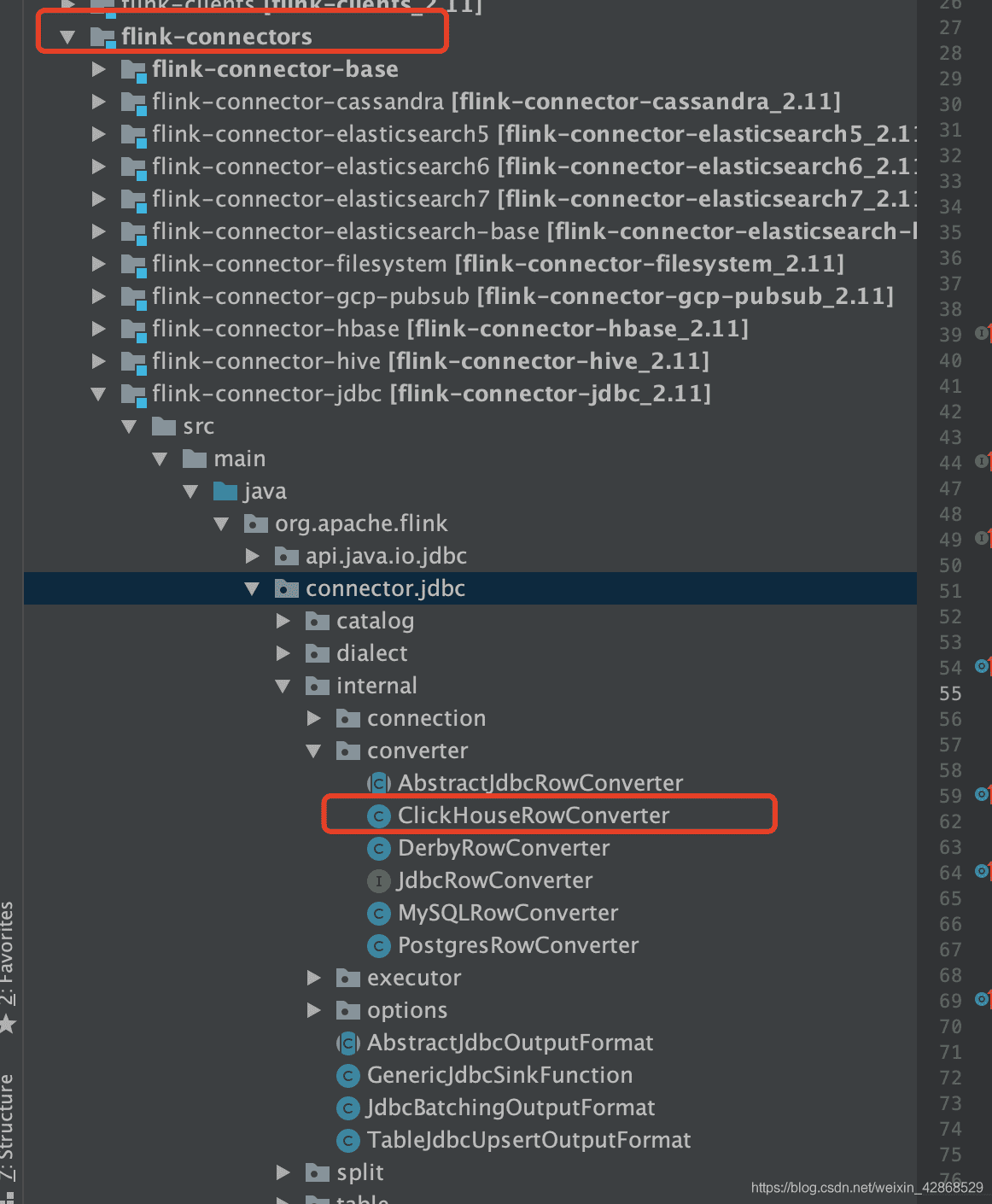
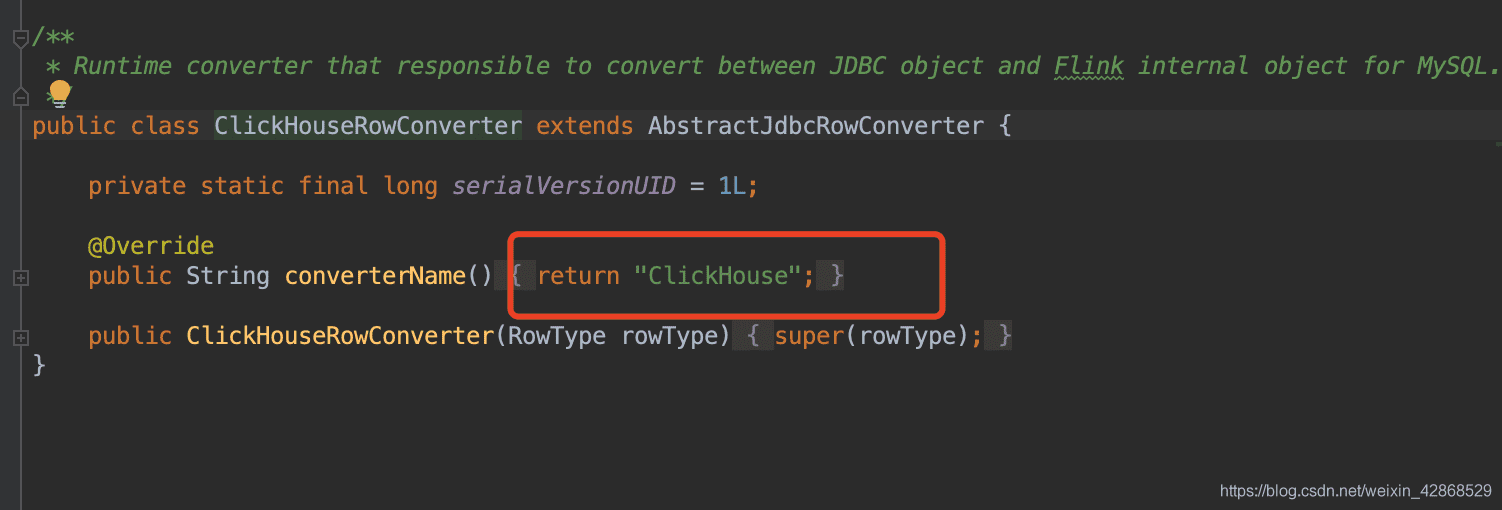
# 三、打包,上传
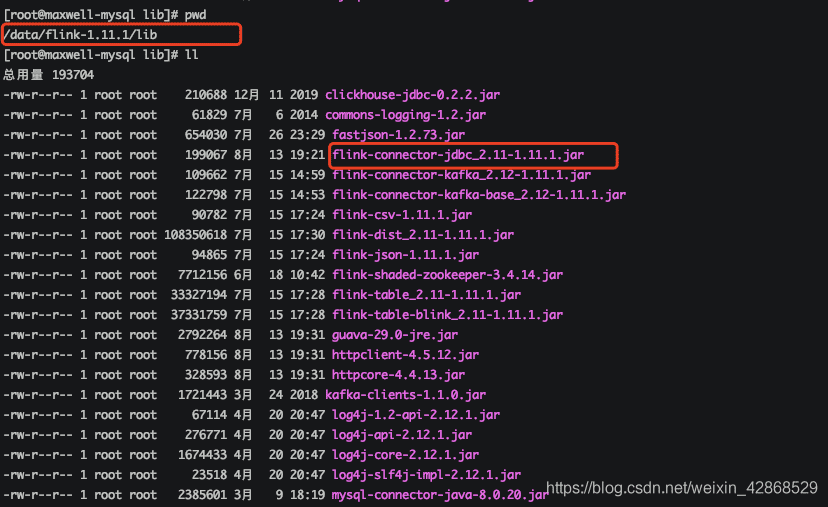
把写好的源码打包上传到flink安装目录的lib目录下,另外,clickhouse和kafka相关的包最好都提前下好,避免运行报错
# 四、测试
跑一个flink shell进行测试
bin/pyflink-shell.sh local
跑之前,需要在clickhouse里建好相应的库表 以下是代码: 把数据写入clickhouse
st_env.sql_update("""CREATE TABLE t(
`class_id` string,
`task_id` string,
`history_id` string,
`id` string
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'smallcourse__learn_record',
'connector.properties.zookeeper.connect' = 'localhost:2181',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'connector.properties.group.id' = 't2',
'connector.startup-mode' = 'latest-offset',
'format.type' = 'json',
'update-mode' = 'append'
)""")
st_env.sql_update("""CREATE TABLE test_lin (
`class_id` string,
`task_id` string,
`history_id` string,
`id` string
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:clickhouse://localhost:8123/demo',
'connector.table' = 'test_lin',
'connector.driver' = 'ru.yandex.clickhouse.ClickHouseDriver',
'connector.username' = '',
'connector.password' = '',
'connector.write.flush.max-rows' = '1'
)""")
d=st_env.sql_query("select class_id,task_id,history_id,id from t")
d.insert_into("test_lin")
st_env.execute("d")
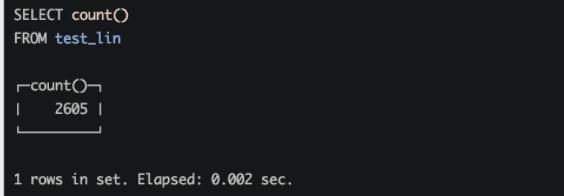
最后: 去clickhouse执行sql
select count() from test_lin;
结果:
# 更新(2021-06-17):
上面的功能比较简单,要用在生产环境还需要自己实现一些功能; 但是目前阿里已经提供了第三方的flink-clickhouse-connector的jar包,下面是阿里云的链接
https://help.aliyun.com/document_detail/185696.html?spm=a2c4g.11186623.6.575.6e19d76clVnHeC

下载完放在flink的lib目录下,然后就可以直接在代码里使用了,但是阿里提供的jar包也只是实现了一些基本数据类型,如果有其他的复杂数据类型需要写到clickhouse,比如MAP,还是需要自己实现。
# 参考文章
- https://zhuanlan.zhihu.com/p/268786701
- https://www.cnblogs.com/qinghualee/articles/14298261.html
- https://blog.csdn.net/weixin_42868529/article/details/107990845










