TIP
本文主要是介绍 HBASE-读写优化 。
HBase性能优化方法总结 (opens new window)
# 1. 表的设计
# 1.1 Pre-Creating Regions
默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡。
有关预分区,详情参见:Table Creation: Pre-Creating Regions (opens new window),下面是一个例子:
public static boolean createTable(HBaseAdmin admin, HTableDescriptor table, byte[][] splits)
throws IOException {
try {
admin.createTable(table, splits);
return true;
} catch (TableExistsException e) {
logger.info("table " + table.getNameAsString() + " already exists");
// the table already exists...
return false;
}
}
public static byte[][] getHexSplits(String startKey, String endKey, int numRegions) {
byte[][] splits = new byte[numRegions-1][];
BigInteger lowestKey = new BigInteger(startKey, 16);
BigInteger highestKey = new BigInteger(endKey, 16);
BigInteger range = highestKey.subtract(lowestKey);
BigInteger regionIncrement = range.divide(BigInteger.valueOf(numRegions));
lowestKey = lowestKey.add(regionIncrement);
for(int i=0; i < numRegions-1;i++) {
BigInteger key = lowestKey.add(regionIncrement.multiply(BigInteger.valueOf(i)));
byte[] b = String.format("%016x", key).getBytes();
splits[i] = b;
}
return splits;
}
# 1.2 Row Key
HBase中row key用来检索表中的记录,支持以下三种方式:
- 通过单个row key访问:即按照某个row key键值进行get操作;
- 通过row key的range进行scan:即通过设置startRowKey和endRowKey,在这个范围内进行扫描;
- 全表扫描:即直接扫描整张表中所有行记录。
在HBase中,row key可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,存为byte[]字节数组,一般设计成定长的。
row key是按照字典序存储,因此,设计row key时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
举个例子:如果最近写入HBase表中的数据是最可能被访问的,可以考虑将时间戳作为row key的一部分,由于是字典序排序,所以可以使用Long.MAX_VALUE - timestamp作为row key,这样能保证新写入的数据在读取时可以被快速命中。
# 1.3 Column Family
不要在一张表里定义太多的****column family。目前Hbase并不能很好的处理超过2~3个column family的表。因为某个column family在flush的时候,它邻近的column family也会因关联效应被触发flush,最终导致系统产生更多的I/O。感兴趣的同学可以对自己的HBase集群进行实际测试,从得到的测试结果数据验证一下。
# 1.4 In Memory
创建表的时候,可以通过HColumnDescriptor.setInMemory(true)将表放到RegionServer的缓存中,保证在读取的时候被cache命中。
# 1.5 Max Version
创建表的时候,可以通过HColumnDescriptor.setMaxVersions(int maxVersions)设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置setMaxVersions(1)。
# 1.6 Time To Live
创建表的时候,可以通过HColumnDescriptor.setTimeToLive(int timeToLive)设置表中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储最近两天的数据,那么可以设置setTimeToLive(2 * 24 * 60 * 60)。
# 1.7 Compact & Split
在HBase中,数据在更新时首先写入WAL 日志(HLog)和内存(MemStore)中,MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。于此同时, 系统会在zookeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了**(minor compact)**。
StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定的阈值后,就会进行一次合并**(major compact),将对同一个key的修改合并到一起,形成一个大的StoreFile,当StoreFile的大小达到一定阈值后,又会对 StoreFile进行分割(split)**,等分为两个StoreFile。
由于对表的更新是不断追加的,处理读请求时,需要访问Store中全部的StoreFile和MemStore,将它们按照row key进行合并,由于StoreFile和MemStore都是经过排序的,并且StoreFile带有内存中索引,通常合并过程还是比较快的。
实际应用中,可以考虑必要时手动进行major compact,将同一个row key的修改进行合并形成一个大的StoreFile。同时,可以将StoreFile设置大些,减少split的发生。
# 2. 写表操作
# 2.1 多HTable并发写
创建多个HTable客户端用于写操作,提高写数据的吞吐量,一个例子:
static final Configuration conf = HBaseConfiguration.create();
static final String table_log_name = “user_log”;
wTableLog = new HTable[tableN];
for (int i = 0; i < tableN; i++) {
wTableLog[i] = new HTable(conf, table_log_name);
wTableLog[i].setWriteBufferSize(5 * 1024 * 1024); //5MB
wTableLog[i].setAutoFlush(false);
}
# 2.2 HTable参数设置
# 2.2.1 Auto Flush
通过调用HTable.setAutoFlush(false)方法可以将HTable写客户端的自动flush关闭,这样可以批量写入数据到HBase,而不是有一条put就执行一次更新,只有当put填满客户端写缓存时,才实际向HBase服务端发起写请求。默认情况下auto flush是开启的。
# 2.2.2 Write Buffer
通过调用HTable.setWriteBufferSize(writeBufferSize)方法可以设置HTable客户端的写buffer大小,如果新设置的buffer小于当前写buffer中的数据时,buffer将会被flush到服务端。其中,writeBufferSize的单位是byte字节数,可以根据实际写入数据量的多少来设置该值。
# 2.2.3 WAL Flag
在HBae中,客户端向集群中的RegionServer提交数据时(Put/Delete操作),首先会先写WAL(Write Ahead Log)日志(即HLog,一个RegionServer上的所有Region共享一个HLog),只有当WAL日志写成功后,再接着写MemStore,然后客户端被通知提交数据成功;如果写WAL日志失败,客户端则被通知提交失败。这样做的好处是可以做到RegionServer宕机后的数据恢复。
因此,对于相对不太重要的数据,可以在Put/Delete操作时,通过调用Put.setWriteToWAL(false)或Delete.setWriteToWAL(false)函数,放弃写WAL日志,从而提高数据写入的性能。
值得注意的是:谨慎选择关闭WAL日志,因为这样的话,一旦RegionServer宕机,Put/Delete的数据将会无法根据WAL日志进行恢复。
# 2.3 批量写
通过调用HTable.put(Put)方法可以将一个指定的row key记录写入HBase,同样HBase提供了另一个方法:通过调用HTable.put(List<Put>)方法可以将指定的row key列表,批量写入多行记录,这样做的好处是批量执行,只需要一次网络I/O开销,这对于对数据实时性要求高,网络传输RTT高的情景下可能带来明显的性能提升。
# 2.4 多线程并发写
在客户端开启多个HTable写线程,每个写线程负责一个HTable对象的flush操作,这样结合定时flush和写buffer(writeBufferSize),可以既保证在数据量小的时候,数据可以在较短时间内被flush(如1秒内),同时又保证在数据量大的时候,写buffer一满就及时进行flush。下面给个具体的例子:
for (int i = 0; i < threadN; i++) {
Thread th = new Thread() {
public void run() {
while (true) {
try {
sleep(1000); //1 second
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (wTableLog[i]) {
try {
wTableLog[i].flushCommits();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
};
th.setDaemon(true);
th.start();
}
# 3. 读表操作
# 3.1 多HTable并发读
创建多个HTable客户端用于读操作,提高读数据的吞吐量,一个例子:
static final Configuration conf = HBaseConfiguration.create();
static final String table_log_name = “user_log”;
rTableLog = new HTable[tableN];
for (int i = 0; i < tableN; i++) {
rTableLog[i] = new HTable(conf, table_log_name);
rTableLog[i].setScannerCaching(50);
}
# 3.2 HTable参数设置
# 3.2.1 Scanner Caching
hbase.client.scanner.caching配置项可以设置HBase scanner一次从服务端抓取的数据条数,默认情况下一次一条。通过将其设置成一个合理的值,可以减少scan过程中next()的时间开销,代价是scanner需要通过客户端的内存来维持这些被cache的行记录。
有三个地方可以进行配置:1)在HBase的conf配置文件中进行配置;2)通过调用HTable.setScannerCaching(int scannerCaching)进行配置;3)通过调用Scan.setCaching(int caching)进行配置。三者的优先级越来越高。
# 3.2.2 Scan Attribute Selection
scan时指定需要的Column Family,可以减少网络传输数据量,否则默认scan操作会返回整行所有Column Family的数据。
# 3.2.3 Close ResultScanner
通过scan取完数据后,记得要关闭ResultScanner,否则RegionServer可能会出现问题(对应的Server资源无法释放)。
# 3.3 批量读
通过调用HTable.get(Get)方法可以根据一个指定的row key获取一行记录,同样HBase提供了另一个方法:通过调用HTable.get(List<Get>)方法可以根据一个指定的row key列表,批量获取多行记录,这样做的好处是批量执行,只需要一次网络I/O开销,这对于对数据实时性要求高而且网络传输RTT高的情景下可能带来明显的性能提升。
# 3.4 多线程并发读
在客户端开启多个HTable读线程,每个读线程负责通过HTable对象进行get操作。下面是一个多线程并发读取HBase,获取店铺一天内各分钟PV值的例子:
public class DataReaderServer {
//获取店铺一天内各分钟PV值的入口函数
public static ConcurrentHashMap<String, String> getUnitMinutePV(long uid, long startStamp, long endStamp){
long min = startStamp;
int count = (int)((endStamp - startStamp) / (60*1000));
List<String> lst = new ArrayList<String>();
for (int i = 0; i <= count; i++) {
min = startStamp + i * 60 * 1000;
lst.add(uid + "_" + min);
}
return parallelBatchMinutePV(lst);
}
//多线程并发查询,获取分钟PV值
private static ConcurrentHashMap<String, String> parallelBatchMinutePV(List<String> lstKeys){
ConcurrentHashMap<String, String> hashRet = new ConcurrentHashMap<String, String>();
int parallel = 3;
List<List<String>> lstBatchKeys = null;
if (lstKeys.size() < parallel ){
lstBatchKeys = new ArrayList<List<String>>(1);
lstBatchKeys.add(lstKeys);
}
else{
lstBatchKeys = new ArrayList<List<String>>(parallel);
for(int i = 0; i < parallel; i++ ){
List<String> lst = new ArrayList<String>();
lstBatchKeys.add(lst);
}
for(int i = 0 ; i < lstKeys.size() ; i ++ ){
lstBatchKeys.get(i%parallel).add(lstKeys.get(i));
}
}
List<Future< ConcurrentHashMap<String, String> >> futures = new ArrayList<Future< ConcurrentHashMap<String, String> >>(5);
ThreadFactoryBuilder builder = new ThreadFactoryBuilder();
builder.setNameFormat("ParallelBatchQuery");
ThreadFactory factory = builder.build();
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(lstBatchKeys.size(), factory);
for(List<String> keys : lstBatchKeys){
Callable< ConcurrentHashMap<String, String> > callable = new BatchMinutePVCallable(keys);
FutureTask< ConcurrentHashMap<String, String> > future = (FutureTask< ConcurrentHashMap<String, String> >) executor.submit(callable);
futures.add(future);
}
executor.shutdown();
// Wait for all the tasks to finish
try {
boolean stillRunning = !executor.awaitTermination(
5000000, TimeUnit.MILLISECONDS);
if (stillRunning) {
try {
executor.shutdownNow();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} catch (InterruptedException e) {
try {
Thread.currentThread().interrupt();
} catch (Exception e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
// Look for any exception
for (Future f : futures) {
try {
if(f.get() != null)
{
hashRet.putAll((ConcurrentHashMap<String, String>)f.get());
}
} catch (InterruptedException e) {
try {
Thread.currentThread().interrupt();
} catch (Exception e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
} catch (ExecutionException e) {
e.printStackTrace();
}
}
return hashRet;
}
//一个线程批量查询,获取分钟PV值
protected static ConcurrentHashMap<String, String> getBatchMinutePV(List<String> lstKeys){
ConcurrentHashMap<String, String> hashRet = null;
List<Get> lstGet = new ArrayList<Get>();
String[] splitValue = null;
for (String s : lstKeys) {
splitValue = s.split("_");
long uid = Long.parseLong(splitValue[0]);
long min = Long.parseLong(splitValue[1]);
byte[] key = new byte[16];
Bytes.putLong(key, 0, uid);
Bytes.putLong(key, 8, min);
Get g = new Get(key);
g.addFamily(fp);
lstGet.add(g);
}
Result[] res = null;
try {
res = tableMinutePV[rand.nextInt(tableN)].get(lstGet);
} catch (IOException e1) {
logger.error("tableMinutePV exception, e=" + e1.getStackTrace());
}
if (res != null && res.length > 0) {
hashRet = new ConcurrentHashMap<String, String>(res.length);
for (Result re : res) {
if (re != null && !re.isEmpty()) {
try {
byte[] key = re.getRow();
byte[] value = re.getValue(fp, cp);
if (key != null && value != null) {
hashRet.put(String.valueOf(Bytes.toLong(key,
Bytes.SIZEOF_LONG)), String.valueOf(Bytes
.toLong(value)));
}
} catch (Exception e2) {
logger.error(e2.getStackTrace());
}
}
}
}
return hashRet;
}
}
//调用接口类,实现Callable接口
class BatchMinutePVCallable implements Callable<ConcurrentHashMap<String, String>>{
private List<String> keys;
public BatchMinutePVCallable(List<String> lstKeys ) {
this.keys = lstKeys;
}
public ConcurrentHashMap<String, String> call() throws Exception {
return DataReadServer.getBatchMinutePV(keys);
}
}
# 3.5 缓存查询结果
对于频繁查询HBase的应用场景,可以考虑在应用程序中做缓存,当有新的查询请求时,首先在缓存中查找,如果存在则直接返回,不再查询HBase;否则对HBase发起读请求查询,然后在应用程序中将查询结果缓存起来。至于缓存的替换策略,可以考虑LRU等常用的策略。
# 3.6 Blockcache
HBase上Regionserver的内存分为两个部分,一部分作为Memstore,主要用来写;另外一部分作为BlockCache,主要用于读。
写请求会先写入Memstore,Regionserver会给每个region提供一个Memstore,当Memstore满64MB以后,会启动 flush刷新到磁盘。当Memstore的总大小超过限制时(heapsize * hbase.regionserver.global.memstore.upperLimit * 0.9),会强行启动flush进程,从最大的Memstore开始flush直到低于限制。
读请求先到Memstore中查数据,查不到就到BlockCache中查,再查不到就会到磁盘上读,并把读的结果放入BlockCache。由于BlockCache采用的是LRU策略,因此BlockCache达到上限(heapsize * hfile.block.cache.size * 0.85)后,会启动淘汰机制,淘汰掉最老的一批数据。
一个Regionserver上有一个BlockCache和N个Memstore,它们的大小之和不能大于等于heapsize * 0.8,否则HBase不能启动。默认BlockCache为0.2,而Memstore为0.4。对于注重读响应时间的系统,可以将 BlockCache设大些,比如设置BlockCache=0.4**,Memstore=0.39,以加大缓存的命中率。**
有关BlockCache机制,请参考这里:HBase的Block cache (opens new window),HBase的blockcache机制 (opens new window),hbase中的缓存的计算与使用 (opens new window)。
# 【----------------------------】
# HBase查询优化
# 1.概述
HBase是一个实时的非关系型数据库,用来存储海量数据。但是,在实际使用场景中,在使用HBase API查询HBase中的数据时,有时会发现数据查询会很慢。本篇博客将从客户端优化和服务端优化两个方面来介绍,如何提高查询HBase的效率。
# 2.内容
这里,我们先给大家介绍如何从客户端优化查询速度。
# 2.1 客户端优化
客户端查询HBase,均通过HBase API的来获取数据,如果在实现代码逻辑时使用API不当,也会造成读取耗时严重的情况。
# 2.1.1 Scan优化
在使用HBase的Scan接口时,一次Scan会返回大量数据。客户端向HBase发送一次Scan请求,实际上并不会将所有数据加载到本地,而是通过多次RPC请求进行加载。这样设计的好处在于避免大量数据请求会导致网络带宽负载过高影响其他业务使用HBase,另外从客户端的角度来说可以避免数据量太大,从而本地机器发送OOM(内存溢出)。
默认情况下,HBase每次Scan会缓存100条,可以通过属性hbase.client.scanner.caching来设置。另外,最大值默认为-1,表示没有限制,具体实现见源代码:
/**
* @return the maximum result size in bytes. See {@link #setMaxResultSize(long)}
*/
public long getMaxResultSize() {
return maxResultSize;
}
/**
* Set the maximum result size. The default is -1; this means that no specific
* maximum result size will be set for this scan, and the global configured
* value will be used instead. (Defaults to unlimited).
*
* @param maxResultSize The maximum result size in bytes.
*/
public Scan setMaxResultSize(long maxResultSize) {
this.maxResultSize = maxResultSize;
return this;
}
一般情况下,默认缓存100就可以满足,如果数据量过大,可以适当增大缓存值,来减少RPC次数,从而降低Scan的总体耗时。另外,在做报表呈现时,建议使用HBase分页来返回Scan的数据。
# 2.1.2 Get优化
HBase系统提供了单条get数据和批量get数据,单条get通常是通过请求表名+rowkey,批量get通常是通过请求表名+rowkey集合来实现。客户端在读取HBase的数据时,实际是与RegionServer进行数据交互。在使用批量get时可以有效的较少客户端到各个RegionServer之间RPC连接数,从而来间接的提高读取性能。批量get实现代码见org.apache.hadoop.hbase.client.HTable类:
public Result[] get(List<Get> gets) throws IOException {
if (gets.size() == 1) {
return new Result[]{get(gets.get(0))};
}
try {
Object[] r1 = new Object[gets.size()];
batch((List<? extends Row>)gets, r1, readRpcTimeoutMs);
// Translate.
Result [] results = new Result[r1.length];
int i = 0;
for (Object obj: r1) {
// Batch ensures if there is a failure we get an exception instead
results[i++] = (Result)obj;
}
return results;
} catch (InterruptedException e) {
throw (InterruptedIOException)new InterruptedIOException().initCause(e);
}
}
从实现的源代码分析可知,批量get请求的结果,要么全部返回,要么抛出异常。
# 2.1.3 列簇和列优化
通常情况下,HBase表设计我们一个指定一个列簇就可以满足需求,但也不排除特殊情况,需要指定多个列簇(官方建议最多不超过3个),其实官方这样建议也是有原因的,HBase是基于列簇的非关系型数据库,意味着相同的列簇数据会存放在一起,而不同的列簇的数据会分开存储在不同的目录下。如果一个表设计多个列簇,在使用rowkey查询而不限制列簇,这样在检索不同列簇的数据时,需要独立进行检索,查询效率固然是比指定列簇查询要低的,列簇越多,这样影响越大。
而同一列簇下,可能涉及到多个列,在实际查询数据时,如果一个表的列簇有上1000+的列,这样一个大表,如果不指定列,这样查询效率也是会很低。通常情况下,在查询的时候,可以查询指定我们需要返回结果的列,对于不需要的列,可以不需要指定,这样能够有效地的提高查询效率,降低延时。
# 2.1.4 禁止缓存优化
批量读取数据时会全表扫描一次业务表,这种提现在Scan操作场景。在Scan时,客户端与RegionServer进行数据交互(RegionServer的实际数据时存储在HDFS上),将数据加载到缓存,如果加载很大的数据到缓存时,会对缓存中的实时业务热数据有影响,由于缓存大小有限,加载的数据量过大,会将这些热数据“挤压”出去,这样当其他业务从缓存请求这些数据时,会从HDFS上重新加载数据,导致耗时严重。
在批量读取(T+1)场景时,建议客户端在请求是,在业务代码中调用setCacheBlocks(false)函数来禁止缓存,默认情况下,HBase是开启这部分缓存的。源代码实现为:
/**
* Set whether blocks should be cached for this Get.
* <p>
* This is true by default. When true, default settings of the table and
* family are used (this will never override caching blocks if the block
* cache is disabled for that family or entirely).
*
* @param cacheBlocks if false, default settings are overridden and blocks
* will not be cached
*/
public Get setCacheBlocks(boolean cacheBlocks) {
this.cacheBlocks = cacheBlocks;
return this;
}
/**
* Get whether blocks should be cached for this Get.
* @return true if default caching should be used, false if blocks should not
* be cached
*/
public boolean getCacheBlocks() {
return cacheBlocks;
}
# 2.2 服务端优化
HBase服务端配置或集群有问题,也会导致客户端读取耗时较大,集群出现问题,影响的是整个集群的业务应用。
# 2.2.1 负载均衡优化
客户端的请求实际上是与HBase集群的每个RegionServer进行数据交互,在细分一下,就是与每个RegionServer上的某些Region进行数据交互,每个RegionServer上的Region个数上的情况下,可能这种耗时情况影响不大,体现不够明显。但是,如果每个RegionServer上的Region个数较大的话,这种影响就会很严重。笔者这里做过统计的数据统计,当每个RegionServer上的Region个数超过800+,如果发生负载不均衡,这样的影响就会很严重。
可能有同学会有疑问,为什么会发送负载不均衡?负载不均衡为什么会造成这样耗时严重的影响?
# 1.为什么会发生负载不均衡?
负载不均衡的影响通常由以下几个因素造成:
- 没有开启自动负载均衡
- 集群维护,扩容或者缩减RegionServer节点
- 集群有RegionServer节点发生宕机或者进程停止,随后守护进程又自动拉起宕机的RegionServer进程
针对这些因素,可以通过以下解决方案来解决:
- 开启自动负载均衡,执行命令:echo "balance_switch true" | hbase shell
- 在维护集群,或者守护进程拉起停止的RegionServer进程时,定时调度执行负载均衡命令:echo "balancer" | hbase shell
# 2.负载不均衡为什么会造成这样耗时严重的影响?
这里笔者用一个例子来说,集群每个RegionServer包含由800+的Region数,但是,由于集群维护,有几台RegionServer节点的Region全部集中到一台RegionServer,分布如下图所示:
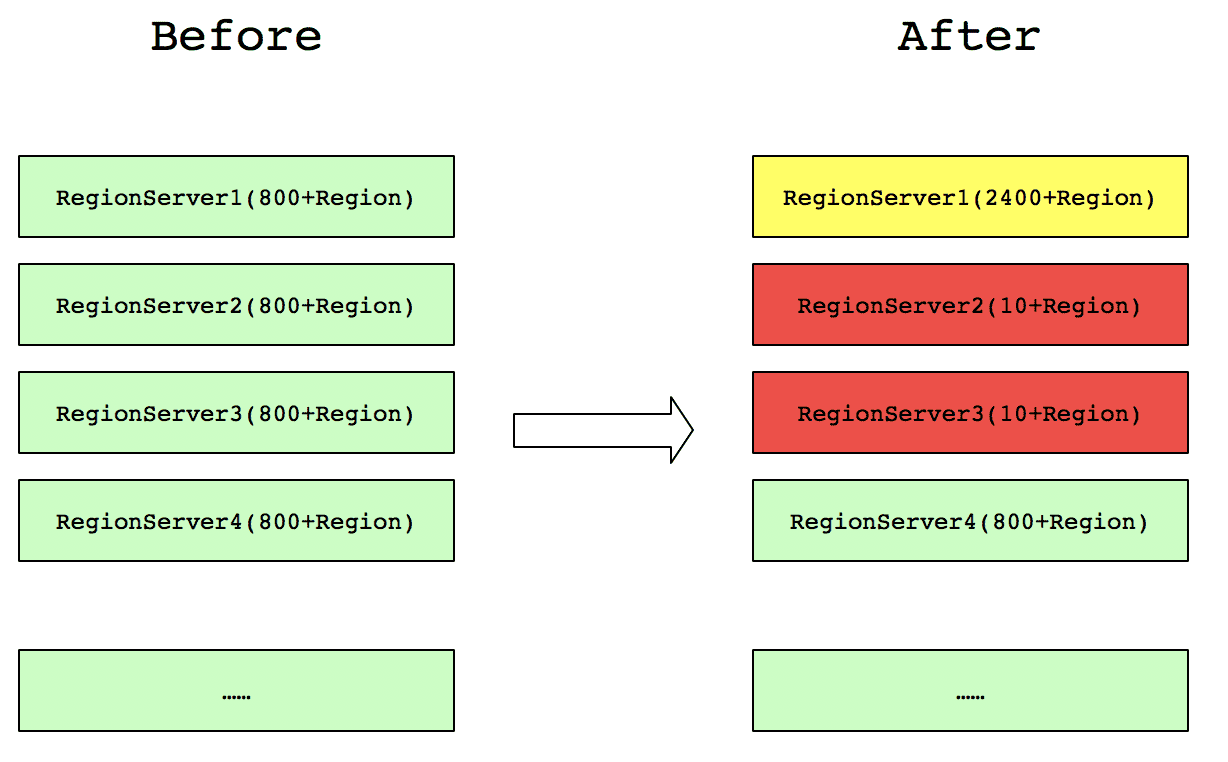
这样之前请求在RegionServer2和RegionServer3上的,都会集中到RegionServer1上去请求。这样就不能发挥整个集群的并发处理能力,另外,RegionServer1上的资源使用将会翻倍(比如网络、磁盘IO、HBase RPC的Handle数等)。而原先其他正常业务到RegionServer1的请求也会因此受到很大的影响。因此,读取请求不均衡不仅会造成本身业务性能很长,还会严重影响其他正常业务的查询。同理,写请求不均衡,也会造成类似的影响。故HBase负载均衡是HBase集群性能的重要体现。
# 2.2.2 BlockCache优化
BlockCache作为读缓存,合理设置对于提高读性能非常重要。默认情况下,BlockCache和Memstore的配置各站40%,可以通过在hbase-site.xml配置以下属性来实现:
- hfile.block.cache.size,默认0.4,用来提高读性能
- hbase.regionserver.global.memstore.size,默认0.4,用来提高写性能
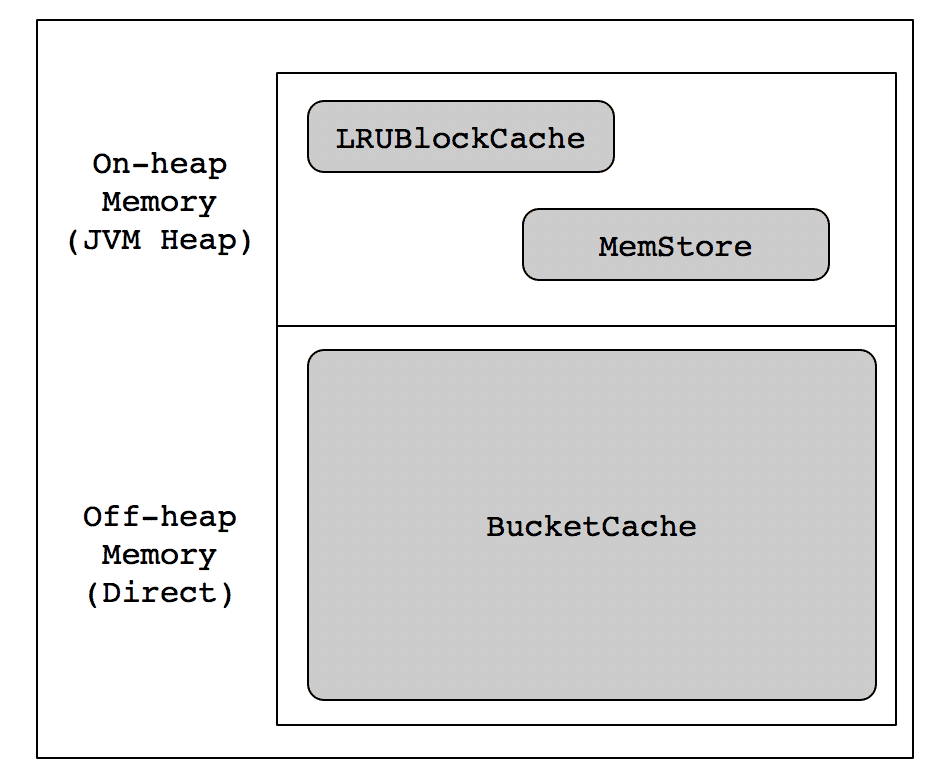
本篇博客主要介绍提高读性能,这里我们可以将BlockCache的占比设置大一些,Memstore的占比设置小一些(总占比保持在0.8即可)。另外,BlockCache的策略选择也是很重要的,不同的策略对于读性能来说影响不大,但是对于GC的影响却比较明显,在设置hbase.bucketcache.ioengine属性为offheap时,GC表现的很优秀。缓存结构如下图所示:
设置BlockCache可以在hbase-site.xml文件中,配置如下属性:
<!-- 分配的内存大小尽可能的多些,前提是不能超过 (机器实际物理内存-JVM内存) -->
<property>
<name>hbase.bucketcache.size</name>
<value>16384</value>
</property>
<property>
<name>hbase.bucketcache.ioengine</name>
<value>offheap</value>
</property>
设置块内存大小,可以参考入下表格:
| 标号 | 描述 | 计算公式或值 | 结果 |
|---|---|---|---|
| A | 物理内存选择:on-heap(JVM)+off-heap(Direct) | 单台物理节点内存值,单位MB | 262144 |
| B | HBASE_HEAPSIZE('-Xmx) | 单位MB | 20480 |
| C | -XX:MaxDirectMemorySize,off-heap允许的最大内存值 | A-B | 241664 |
| Dp | hfile.block.cache.size和hbase.regionserver.global.memstore.size总和不要超过0.8 | 读取比例占比*0.8 | 0.5*0.8=0.4 |
| Dm | JVM Heap允许的最大BlockCache(MB) | B*Dp | 20480*0.4=8192 |
| Ep | hbase.regionserver.global.memstore.size设置的最大JVM值 | 0.8-Dp | 0.8-0.4=0.4 |
| F | 用于其他用途的off-heap内存,例如DFSClient | 推荐1024到2048 | 2048 |
| G | BucketCache允许的off-heap内存 | C-F | 241664-2048=239616 |
另外,BlockCache策略,能够有效的提高缓存命中率,这样能够间接的提高热数据覆盖率,从而提升读取性能。
# 2.2.3 HFile优化
HBase读取数据时会先从BlockCache中进行检索(热数据),如果查询不到,才会到HDFS上去检索。而HBase存储在HDFS上的数据以HFile的形式存在的,文件如果越多,检索所花费的IO次数也就必然增加,对应的读取耗时也就增加了。文件数量取决于Compaction的执行策略,有以下2个属性有关系:
- hbase.hstore.compactionThreshold,默认为3,表示store中文件数超过3个就开始进行合并操作
- hbase.hstore.compaction.max.size,默认为9223372036854775807,合并的文件最大阀值,超过这个阀值的文件不能进行合并
另外,hbase.hstore.compaction.max.size值可以通过实际的Region总数来计算,公式如下:
hbase.hstore.compaction.max.size = RegionTotal / hbase.hstore.compactionThreshold
# 2.2.4 Compaction优化
Compaction操作是将小文件合并为大文件,提高后续业务随机读取的性能,但是在执行Compaction操作期间,节点IO、网络带宽等资源会占用较多,那么什么时候执行Compaction才最好?什么时候需要执行Compaction操作?
# 1.什么时候执行Compaction才最好?
实际应用场景中,会关闭Compaction自动执行策略,通过属性hbase.hregion.majorcompaction来控制,将hbase.hregion.majorcompaction=0,就可以禁止HBase自动执行Compaction操作。一般情况下,选择集群负载较低,资源空闲的时间段来定时调度执行Compaction。
如果合并的文件较多,可以通过设置如下属性来提生Compaction的执行速度,配置如下:
<property>
<name>hbase.regionserver.thread.compaction.large</name>
<value>8</value>
<description></description>
</property>
<property>
<name>hbase.regionserver.thread.compaction.small</name>
<value>5</value>
<description></description>
</property>
# 2.什么时候需要执行Compaction操作?
一般维护HBase集群后,由于集群发生过重启,HBase数据本地性较低,通过HBase页面可以观察,此时如果不执行Compaction操作,那么客户端查询的时候,需要跨副本节点去查询,这样来回需要经过网络带宽,对比正常情况下,从本地节点读取数据,耗时是比较大的。在执行Compaction操作后,HBase数据本地性为1,这样能够有效的提高查询效率。
# 3.总结
本篇博客HBase查询优化从客户端和服务端角度,列举一些常见有效地优化手段。当然,优化还需要从自己实际应用场景出发,例如代码实现逻辑、物理机的实际配置等方面来设置相关参数。大家可以根据实际情况来参考本篇博客进行优化。
# 参考文章
- https://www.cnblogs.com/erbing/p/9869730.html
- https://www.cnblogs.com/smartloli/p/9425343.html
← HBASE-配置优化 HBASE-系统架构 →










