TIP
本文主要是介绍 BM算法(Boyer-Moore) 。
# BM算法介绍
BM算法(Boyer-Moore算法)是罗伯特·波义尔(Robert Boyer)和杰·摩尔(J·Moore)在1977年共同提出的。与KMP算法不同的是,BM算法是模式串P由左向右移动,而字符的比较时由右向左进行。当文本字符与模式不匹配时,则根据预先定义好的“坏字符串偏移函数”和“好后缀偏移函数”计算出偏移量。它的简化版本BMH或整个算法通常在文本编辑器中用于“搜索”和“替代”命令。该算法从最右边的字符开始,从右到左扫描模式的字符。如果不匹配(或整个模式完全匹配),它将使用两个预先计算的函数将窗口向右移动。这两个移位函数称为***后缀移位***(也称为匹配移位)和***字符移位***(也称为出现移位)。
# 坏字符启发式
这种方法称为坏字符启发法。 如果错误字符(即导致不匹配的文本符号)出现在模式中的其他位置,则也可以应用此功能。 然后可以移动模式,使其与该文本符号对齐。 下一个示例说明了这种情况。
Example:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... |
|---|---|---|---|---|---|---|---|---|---|---|
| a | b | b | a | b | a | b | a | c | b | a |
| b | a | b | a | c | ||||||
| b | a | b | a | c |
比较b-c导致不匹配。文本符号b出现在图案中的位置0和2处。可以移动该模式,以使模式中最右边的b与文本符号b对齐。
# 坏字符启发式预处理
坏字符偏移是一个容量为σ的表,其中σ表示目标字符串中元素的种类数,每个字符对应的Ascall表中的十进制为下标。对于坏字符启发法,需要一个函数 ooc,该函数会针对字母表中的每个符号产生其在模式中最右边出现的位置;如果在模式中未出现该符号,则得出-1。
令p = P∈A“,P0 ... PM-1 (模式的)和 a∈A 一个字母符号。然后 ooc(p, a) = max{ j | pj = a },这里max(∅) = -1。
Example:
- ooc(text, x) = 2
- ooc(text, t) = 3
字符串“文本”中符号“ x”最右出现在位置2。符号“ t”出现在位置0和3,最右边出现在位置3。
某个模式p的出现函数存储在数组ooc中,该数组由字母符号索引。 对于每个符号A,相应的值ooc(p,a) 存储在 ooc[a]中。
# 代码
1 /**
2 * 计算字符在模式最后出现位置
3 */
4 private void bmInitocc() {
5 char a;
6 int j;
7 // 初始化所有字符出现为-1
8 for (a = 0; a < alphabetSize; a++) {
9 occ[a] = -1;
10 }
11 // 填充每种字符最后出现的位置
12 for (j = 0; j < m; j++) {
13 a = p[j];
14 occ[a] = j;
15 }
16 }
# 好后缀启发式
有时,坏字符启发法会失败。 在以下情况下,比较a-b会导致不匹配。 模式符号a的最右出现与文本符号a的对齐将产生负向偏移。 相反,可能会移位1。 但是,在这种情况下,最好从图案的结构中得出最大可能的移位距离。 此方法称为好后缀试探法。
Example:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... |
|---|---|---|---|---|---|---|---|---|---|---|
| a | b | a | a | b | a | b | a | c | b | a |
| c | a | b | a | b | ||||||
| c | a | b | a | b |
后缀ab已匹配。可以移动模式,直到模式中下一个出现的ab对准文本符号ab,即位置2。
在以下情况下,后缀ab已匹配。模式中没有其他出现ab的情况,因此可以将模式移到ab后面,即移至位置5。
Example:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... |
|---|---|---|---|---|---|---|---|---|---|---|
| a | b | c | a | b | a | b | a | c | b | a |
| c | b | a | a | b | ||||||
| c | b | a | a | b |
在以下情况下,后缀bab已匹配。 模式中没有其他出现bab的情况。 但是在这种情况下,模式不能像以前一样移至位置5,而只能移至位置3,因为模式(ab)的前缀与bab的结尾匹配。 我们将此情况称为良好后缀启发式的情况2。
Example:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... |
|---|---|---|---|---|---|---|---|---|---|---|
| a | a | b | a | b | a | b | a | c | b | a |
| a | b | b | a | b | ||||||
| a | b | b | a | b |
模式由坏字符和后缀启发式方法给出的两个距离中的最长的移位。
# 后缀启发式的预处理
对于后缀启发式,使用数组 s。 如果在位置i-1处发生不匹配,即如果从位置i开始的模式后缀已匹配,则每个条目s [i]都包含模式的移位距离。 为了确定移动距离,必须考虑两种情况。
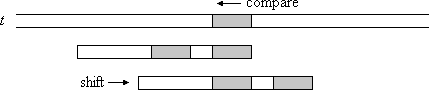
情况1:匹配的后缀出现在模式中的其他位置(图1)。
Figure 1: The matching suffix (gray) occurs somewhere else in the pattern
 )
)
图1:匹配的后缀(灰色)出现在模式中的其他位置
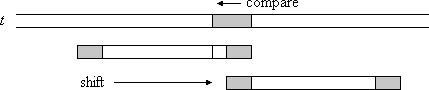
情况2:只有部分匹配的后缀出现在模式的开头(图2)。
Figure 2: Only a part of the matching suffix occurs at the beginning of the pattern
 )
)
图2:匹配后缀的仅一部分出现在模式的开头
# 情况1:
这种情况类似于Knuth-Morris-Pratt预处理。 匹配的后缀是模式后缀的边界。 因此,必须确定模式后缀的边界。 但是,现在需要在给定边界和具有该边界的模式的最短后缀之间进行逆映射。
而且,必须使边界不能由同一字符向左扩展,因为这会在模式串移位后引起另一个不匹配。
在预处理算法的以下第一部分中,将计算数组 f。 每个条目bpos [i]都包含模式后缀的最宽边界的起始位置,起始位置为i。 从位置m开始的后缀ε没有边界,因此f[m]设置为m + 1。
与Knuth-Morris-Pratt(KMP)预处理算法相似,每个边界都是通过检查是否可以用同一字符向左扩展已知的较短边界来计算的。
但是,边界不能向左扩展的情况也很有趣,因为如果发生不匹配,这会导致模式有希望的偏移。 因此,相应的移动距离保存在数组s中,前提是该条目尚未被占用。 后者是较短后缀具有相同边框的情况。
1 /**
2 * 根据模式进行预处理(1/2)
3 */
4 private void bmPreprocess1() {
5 int i = m, j = m + 1;
6 f[i] = j;
7 while (i > 0) {
8 while (j <= m && p[i - 1] != p[j - 1]) {
9 if (s[j] == 0) s[j] = j - i;
10 j = f[j];
11 }
12 i--;
13 j--;
14 f[i] = j;
15 }
16 }
Example:
| i: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| p: | a | b | b | a | b | a | b | |
| f: | 5 | 6 | 4 | 5 | 6 | 7 | 7 | 8 |
| s: | 0 | 0 | 0 | 0 | 2 | 0 | 4 | 1 |
从位置2开始的后缀babab的最宽边界是bab,从位置4开始。因此,f [2] =4。从位置5开始的后缀ab的最宽边界是ε,从位置7开始。因此,f [5] = 7。
数组s的值由不能向左扩展的边界确定。
从位置2开始的后缀babab具有从位置4开始的边界bab。由于p [1]≠p [3],因此该边界无法向左扩展。 差异4 – 2 = 2是bab匹配时的移位距离,然后发生不匹配。 因此,s [4] = 2。
从位置2开始的后缀babab也具有从位置6开始的边界b。此边界也不能扩展。 如果b匹配,则不匹配6 – 2 = 4是移位距离。 因此,s [6] = 4。
从位置6开始的后缀b具有从位置7开始的边界ε。该边界不能向左扩展。 如果没有匹配,即在第一次比较中发生不匹配,则7 – 6 = 1的差就是移动距离。 因此,s [7] = 1。
注:所谓边界就是模式P中从i开始的后缀中,其后缀中的前缀和后缀所匹配的最大公共子串开始的位置,也就是说 f [i] 到 m-1 的那一串 和 i开始往后的那段是一样的。ε是所有前后缀的匹配结果,相当于集合中的空集,没有边界。
# 情况2:
在这种情况下,模式的匹配后缀的一部分出现在模式的开头。 这意味着该部分是模式的边界。 可以将模式移动到其最大匹配边界允许的范围内(图2)。
在情况2的预处理中,对于每个后缀,确定该后缀中包含的模式的最宽边界。
模式最宽边界的起始位置完全存储在f [0]中。 在上面的示例中,该值是5,因为边界ab从位置5开始。
在以下预处理算法中,该值f [0]最初存储在数组s 的所有空闲条目中。 但是,当模式的后缀变得比f [0]短时,算法会继续使用模式的下一个更宽的边界,即f [j]。
1 /**
2 * 根据模式进行预处理(2/2)
3 */
4 private void bmPreprocess2() {
5 int i, j;
6 j = f[0];
7 for (i = 0; i <= m; i++) {
8 if (s[i] == 0) s[i] = j;
9 if (i == j) j = f[j];
10 }
11 }
Example:
| i: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| p: | a | b | b | a | b | a | b | |
| f: | 5 | 6 | 4 | 5 | 6 | 7 | 7 | 8 |
| s: | 5 | 5 | 5 | 5 | 2 | 5 | 4 | 1 |
# 分析
如果文本中模式的匹配项数量恒定,则在最坏的情况下,Boyer-Moore搜索算法会执行O(n)比较。 证明这一点相当困难。通常,Θ(n·m)比较是必要的,例如 如果模式是am,则文本是an。 通过稍微修改算法,即使在一般情况下,比较次数也可以限制为O(n)。如果字母表与模式的长度相比较大,则该算法将对平均值进行 O(n / m)比较。 这是因为由于坏字符启发法,通常有可能将m移位。
# 总结
在遇到不匹配的情况下,Boyer-Moore算法使用两种不同的启发式方法来确定最大可能的移位距离:“坏字符”和“好后缀”启发式方法。 两种启发式方法都可以导致m的移位距离。 如果第一次比较导致不匹配,并且模式中根本没有出现相应的文本符号,那么对于坏字符启发式就是这种情况。 对于好后缀启发式法,如果只有第一个比较是匹配项,但该字符不在模式中的其他位置出现,则为这种情况。
好后缀启发式算法的预处理相当难以理解和实现。 因此,有时会找到Boyer-Moore算法的版本,在该版本中,好后缀启发式法被遗弃了。 有观点认为,坏字符启发法就足够了,而好后缀启发法不会节省很多比较。 但是,对于字符数量小的字母串而言,情况并非如此。
# 源代码:
1 package algorithm;
2
3 public class BM {
4 private static String name = "Boyer-Moore";
5 private static int alphabetSize = 256;
6 private char[] p, t; // 模式,文本
7 private int m, n; // 模式的长度,文本的长度
8 private int[] occ; // 记录文本字符在模式中的位置
9 private String matches; // 匹配位置
10 private char[] showmatches; // 显示匹配的字符数组
11 private int[] f;
12 private int[] s;
13
14 public BM() {
15 occ = new int[alphabetSize];
16 }
17
18 public void search(String tt, String pp) {
19 setText(tt);
20 setPatten(pp);
21 bmSearch();
22 }
23
24 /**
25 * 设置文本
26 *
27 * @param tt
28 */
29 private void setText(String tt) {
30 n = tt.length();
31 t = tt.toCharArray();
32 initMatches();
33 }
34
35 /**
36 * 设置模式
37 *
38 * @param pp
39 */
40 private void setPatten(String pp) {
41 m = pp.length();
42 p = pp.toCharArray();
43 f = new int[m + 1];
44 s = new int[m + 1];
45 bmPreprocess();
46 }
47
48 /**
49 * 计算字符在模式最后出现位置
50 */
51 private void bmInitocc() {
52 char a;
53 int j;
54 for (a = 0; a < alphabetSize; a++) {
55 occ[a] = -1;
56 }
57 for (j = 0; j < m; j++) {
58 a = p[j];
59 occ[a] = j;
60 }
61 }
62
63 /**
64 * 根据模式进行预处理(1/2)
65 */
66 private void bmPreprocess1() {
67 int i = m, j = m + 1;
68 f[i] = j;
69 while (i > 0) {
70 while (j <= m && p[i - 1] != p[j - 1]) {
71 if (s[j] == 0) s[j] = j - i;
72 j = f[j];
73 }
74 i--;
75 j--;
76 f[i] = j;
77 }
78 }
79
80 /**
81 * 根据模式进行预处理(2/2)
82 */
83 private void bmPreprocess2() {
84 int i, j;
85 j = f[0];
86 for (i = 0; i <= m; i++) {
87 if (s[i] == 0) s[i] = j;
88 if (i == j) j = f[j];
89 }
90 }
91
92 /**
93 * 根据模式进行预处理
94 */
95 private void bmPreprocess() {
96 bmInitocc();
97 bmPreprocess1();
98 bmPreprocess2();
99 }
100
101 /**
102 * 初始化匹配位置该显示的数组
103 */
104 private void initMatches() {
105 matches = "";
106 showmatches = new char[n];
107 for (int i = 0; i < n; i++) {
108 showmatches[i] = ' ';
109 }
110 }
111
112 /**
113 * 在文本中搜索所有出现的模式
114 */
115 private void bmSearch() {
116 int i = 0, j;
117 while (i <= n - m) {
118 j = m - 1;
119 while (j >= 0 && p[j] == t[i + j])
120 j--;
121 if (j < 0) {
122 report(i);
123 i += s[0];
124 } else {
125 i += Math.max(s[j + 1], j - occ[t[i + j]]);
126 }
127 }
128 }
129
130 /**
131 * 匹配报告
132 *
133 * @param i
134 */
135 private void report(int i) {
136 matches += i + " ";
137 showmatches[i] = '^';
138 }
139
140 /**
141 * 搜索后返回匹配位置
142 *
143 * @return
144 */
145 public String getMatches() {
146 return matches;
147 }
148
149 /**
150 * 测试主函数
151 *
152 * @param args
153 */
154 public static void main(String[] args) {
155 BM bm = new BM();
156 System.out.println(name);
157 String tt, pp;
158 tt = "abcdabcd";
159 pp = "abc";
160 bm.search(tt, pp);
161 System.out.println(pp);
162 System.out.println(tt);
163 System.out.println(bm.showmatches);
164 System.out.println(bm.getMatches());
165 tt = "abababaa";
166 pp = "aba";
167 bm.search(tt, pp);
168 System.out.println(pp);
169 System.out.println(tt);
170 System.out.println(bm.showmatches);
171 System.out.println(bm.getMatches());
172 }
173 }
# 参考:
[String Matching - Boyer-Moore algorithm]<img class= "zoom-custom-imgs" :src="$withBase('/assets/img/algorithm/strmatch/comm8/bmen.htm)
# 参考文章
- https://www.cnblogs.com/gaochundong/p/string_matching.html
- https://www.cnblogs.com/magic-sea/tag/%E5%AD%97%E7%AC%A6%E4%B8%B2%E5%8C%B9%E9%85%8D%E7%AE%97%E6%B3%95/










