TIP
本文主要是介绍 Logstash-入门介绍 。
# Logstash 简介
# 前言
之前谈了 Elasticsearch 和 Kibana 的安装,作为开源实时日志分析平台 ELK 的一部分,当然少不了 Logstash 。其实 Logstash 的作用就是一个数据收集器,将各种格式各种渠道的数据通过它收集解析之后格式化输出到 Elasticsearch ,最后再由 Kibana 提供的比较友好的 Web 界面进行汇总、分析、搜索。
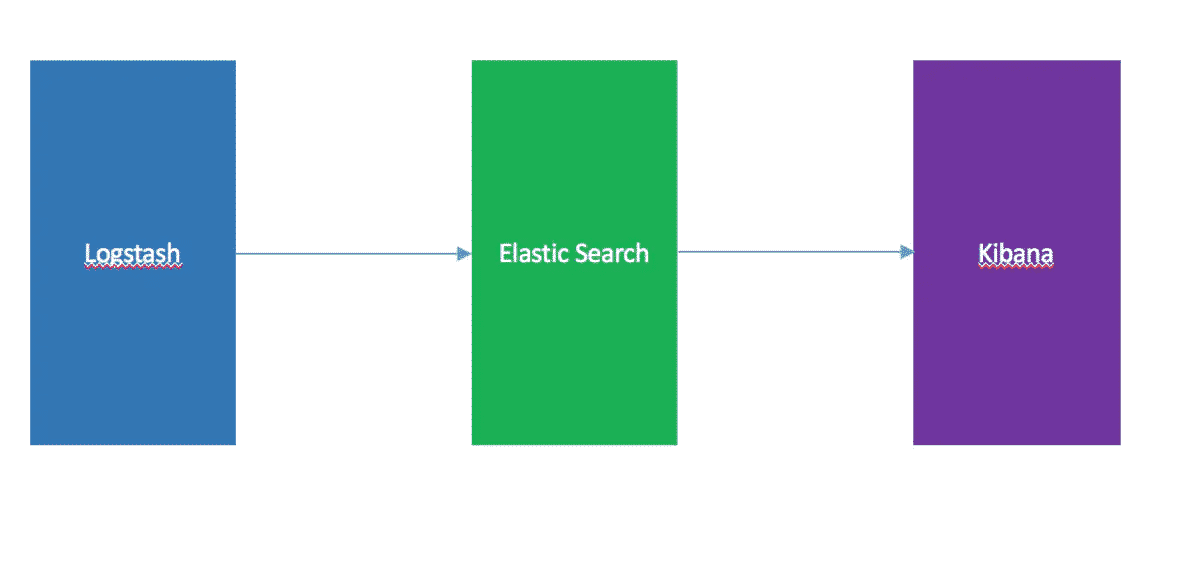
ELK 数据流向
ELK 内部实际就是个管道结构,数据从 Logstash 到 Elasticsearch 再到 Kibana 做可视化展示。这三个组件各自也可以单独使用,比如 Logstash 不仅可以将数据输出到 Elasticsearch ,也可以到数据库、缓存等。下面看看 Logstash 的安装和基本的使用。
# 安装
到官网根据不同操作系统下载最新版本的Logstash压缩包 (opens new window),之后本地解压缩。
# 运行
解压缩之后就可以运行了,在 Logstash 的根目录下执行命令:
bin/logstash -e "input { stdin {}} output { stdout {}}"
控制台输出“Successfully started Logstash API endpoint”表示 Logstash 启动成功

Logstash启动成功
命令里的-e表示后面跟着的是一个配置信息字符串,字符串的功能就是让 Logstash 接受控制台里的输入,并输出到控制台,比如在控制台输入 hello world :
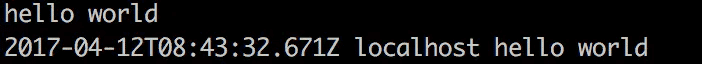
hello world
如果用最简化的方式执行:
bin/logstash -e ""
会看到 Logstash 采用了默认的配置,从控制台输入,并以 json 格式输出到控制台:

json格式输出
# 配置文件
实际运维中配置信息通常会放配置文件中来管理,这种情况下 Logstash 提供了 -f 参数来指定配置信息所在的配置文件。在 Logstash 的根目录下执行命令:
bin/logstash -f config/demo.conf
Logstash 会加载 config 目录中 demo.conf 文件,文件中的内容作为配置信息,看下 demo.conf 文件的内容:
input { stdin {}}
output { stdout {}}
执行命令之后会发现其行为和上面的 -e 配置字符串是一样的,输入什么字符控制台显示什么字符。
# 工作原理
Logstash 内部也是管道的方式进行数据的搜集、处理、输出。在 Logstash 中,包括了三个阶段: 输入 input --> 处理 filter(不是必须的) --> 输出 output
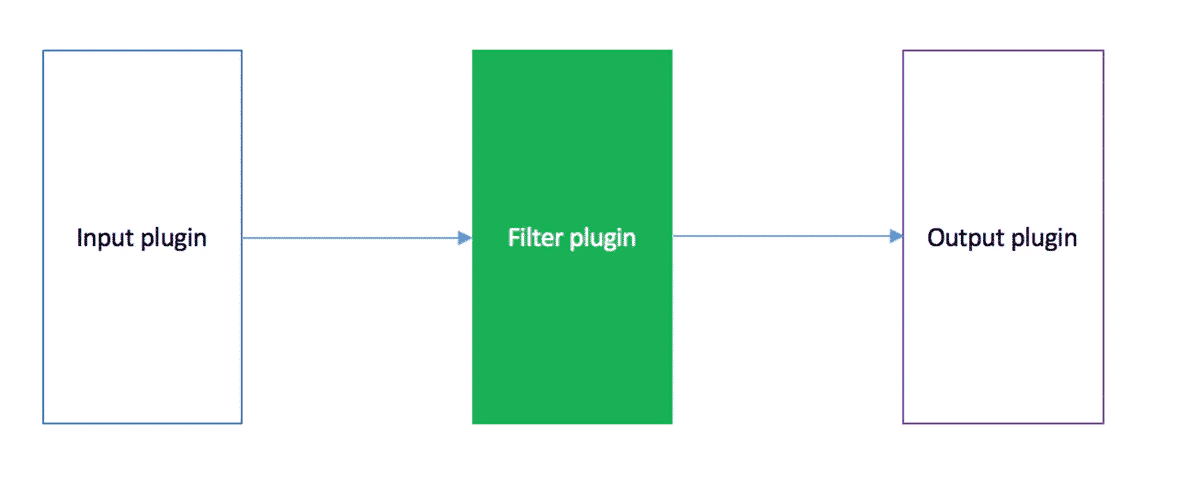
Logstash三个阶段
每个阶段都由很多的插件配合工作,比如 file、elasticsearch、redis 等等。 每个阶段也可以指定多种方式,比如输出既可以输出到 Elasticsearch 中,也可以指定到 stdout 在控制台打印。 正是由于这种插件方式,使得 Logstash 变得易于扩展和定制,下面分别看看这三个阶段的一些插件的使用。
# input-file 插件
看下 input 的一个插件例子。上面讲的是从控制台输入,如果要从文件读取输入,则可以用 file 插件:
input { file { path => "/tmp/abc.log" }}
上面是这个插件的最小化配置, path 后面跟随的是文件的全路径名,如果要匹配一个目录下的所有文件,可以用通配符*:
input { file { path => "/tmp/data/*" } }
要匹配多个不同目录下的文件,则用中括号括起来,并逗号分隔不同文件路径:
input { file { path => ["/tmp/data/*","/log/abc/hello.log"] }}
注意文件的路径名需要时绝对路径。
# output-elasticsearch 插件
如果要将数据输出到,则可以用 Elasticsearch 插件:
output {
elasticsearch {
action => "index"
hosts => "localhost:9200"
index => "log-example"
}
}
上面配置的含义是,将数据输出到 Elasticsearch 服务器,hosts 是提供服务的地址和端口号,action 是指索引到一个文档,index 是指要被写进的索引名,当然还有其他参数配置,具体参见该插件的官方文档说明 (opens new window)
# filter-grok 插件
不论是 input 的 stdin 还是 file 插件,都是从不同来源读取数据,但它们读取的都是一行一行的文本数据,输出的时候会发现它们都是作为一行放到输出的 message 属性中:
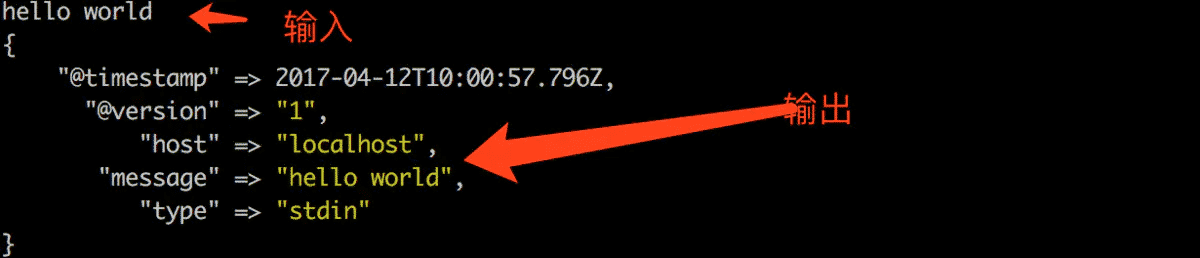
文本输出
很多情况下需要对这些文本做格式化的解析再输出,比如日志文件中数据格式是这样的:
[2017-04-03 23:30:11.020][INFO][logstash] Pipeline main started
上面的文本格式是:[时间][日志级别][模块名]日志信息描述 输出 json 时也希望将时间放到自定义的 TimeStamp 属性中,将日志级别信息放到 LogLevel 属性中,将模块名放到 ModuleName 属性中,将日志信息描述放到 LogDesc 属性中。
如果是这种需求就用到了 grok 插件,该插件是 Logstash 将普通文本解析成结构化数据的最好的方式。(这可不是我非要安利,是官网上说的:Grok is currently the best way in logstash to parse crappy unstructured log data into something structured and queryable.)
- grok 表达式 grok 表达式语法是这样的:
%{SYNTAX:SEMANTIC}
SYNTAX 是要匹配的文本的模式名。SEMANTIC 是匹配出的内容的标识符,该标识符即输出到 output 中的属性名。看一个简单的 grok 表达式例子:
%{IP:source_ip}
它表示使用名为 IP 的正则表达式提取内容,并将匹配出的内容命名为 source_ip 。所以如果输入是 IP 地址的格式:11.22.33.123,则会将该内容放到 source_ip 中。
grok 中预定义的模式 上面的 IP 是 grok 里预定义的模式,其正则表达式的定义实际是:
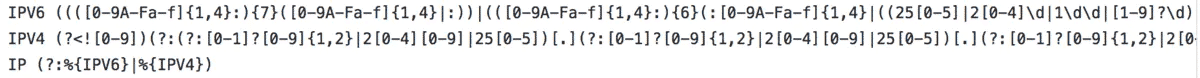
IP 模式定义
grok 已经预定义了很多模式,比如匹配一串数字可以用 NUMBER、匹配 MAC 地址用 MAC、匹配时间用 TIMESTAMP_ISO8601、匹配 LOG 日志级别用 LOGLEVEL
等等。详细定义参见
github 中的说明
grok 中的自定义模式 如果上面列的这些模式不能满足需求,grok 也允许自定义模式。 先看下自定义模式的语法:
pattern_name regexp
pattern_name 就是自定义的模式名,regexp 就是模式的正则表达式定义,之间用一个空格分隔开。比如自定义一个队列 ID 模式,它的格式是10或11个数字、大写字母组成的字符串,其定义语法如下:
QUEUE_ID [0-9A-F]{10,11}
熟悉正则表达是的应该知道[0-9A-F]表示数字、大写字母组成的字符,后面的{10,11}表示有10或11个这样的字符。 接着在 Logstash 根目录下建一个 patterns 目录,该目录下新建一个文件叫 myPattern 。文件内容就是:
QUEUE_ID [0-9A-F]{10,11}
最后在 filter 配置中加上 patterns 目录,并引用上面定义的这个 QUEUE_ID :
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{TIMESTAMP_ISO8601:TimeStamp} %{QUEUE_ID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}
patterns_dir 用于指定自定义模式的文件所在的目录,match 的内容就是 grok 表达式,TIMESTAMP_ISO8601 和 GREEDYDATA 预定义的模式,QUEUE_ID 是自定义的模式。它将匹配以下格式的内容:
2017-04-03 23:30:11.020 12345abcde hello world
匹配后的结果是:
{"@timestamp": "2017-04-12T11:57:40.186Z", "queue_id": "12345abcde", "@version": "1", "syslog_message": "hello world", "message": "2017-04-03 23:30:11.020 12345abcde hello world", "TimeStamp": "2017-04-03 23:30:11.020"}
- 日志文件的 filter 配置 所以上面的日志文件中数据的 filter 区段配置:
filter {
grok {
match => {
"message" => "\[%{TIMESTAMP_ISO8601:TimeStamp}\]\[%{LOGLEVEL:LogLevel}\]\[%{WORD:ModuleName}\] %{GREEDYDATA:LogDesc}"
}
}
}
由于中括号是特殊字符,所以正则表达式中它的前面要加上反斜杠\。 加载文件配置后运行结果如下:

日志信息解析
# 参考文章
- https://www.jianshu.com/p/77bd458cee6f










