TIP
本文主要是介绍 Python-数据挖掘基础 。
# python大数据挖掘系列之基础知识入门
# preface
Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们。
# Python数据分析与挖掘技术概述
所谓数据分析,即对已知的数据进行分析,然后提取出一些有价值的信息,比如统计平均数,标准差等信息,数据分析的数据量可能不会太大,而数据挖掘,是指对大量的数据进行分析与挖倔,得到一些未知的,有价值的信息等,比如从网站的用户和用户行为中挖掘出用户的潜在需求信息,从而对网站进行改善等。
数据分析与数据挖掘密不可分,数据挖掘是对数据分析的提升。数据挖掘技术可以帮助我们更好的发现事物之间的规律。所以我们可以利用数据挖掘技术可以帮助我们更好的发现事物之间的规律。比如发掘用户潜在需求,实现信息的个性化推送,发现疾病与病状甚至病与药物之间的规律等。
# 预先善其事必先利其器
我们首先聊聊数据分析的模块有哪些:
- numpy 高效处理数据,提供数组支持,很多模块都依赖它,比如pandas,scipy,matplotlib都依赖他,所以这个模块都是基础。所以必须先安装numpy。
- pandas 主要用于进行数据的采集与分析
- scipy 主要进行数值计算。同时支持矩阵运算,并提供了很多高等数据处理功能,比如积分,微分方程求样等。
- matplotlib 作图模块,结合其他数据分析模块,解决可视化问题
- statsmodels 这个模块主要用于统计分析
- Gensim 这个模块主要用于文本挖掘
- sklearn,keras 前者机器学习,后者深度学习。
下面就说说这些模块的基础使用。
# numpy模块安装与使用
安装:
下载地址是:http://www.lfd.uci.edu/~gohlke/pythonlibs/
我这里下载的包是1.11.3版本,地址是:http://www.lfd.uci.edu/~gohlke/pythonlibs/f9r7rmd8/numpy-1.11.3+mkl-cp35-cp35m-win_amd64.whl
下载好后,使用pip install "numpy-1.11.3+mkl-cp35-cp35m-win_amd64.whl"
安装的numpy版本一定要是带mkl版本的,这样能够更好支持numpy
# numpy简单使用
import numpy
x=numpy.array([11,22,33,4,5,6,7,]) #创建一维数组
x2=numpy.array([['asfas','asdfsdf','dfdf',11],['1iojasd','123',989012],["jhyfsdaeku","jhgsda"]]) #创建二维数组,注意是([])
x.sort() #排序,没有返回值的,修改原处的值,这里等于修改了X
x.max() # 最大值,对二维数组都管用
x.min() # 最小值,对二维数组都管用
x1=x[1:3] # 取区间,和python的列表没有区别
# 生成随机数
主要使用numpy下的random方法。
#numpy.random.random_integers(最小值,最大值,个数) 获取的是正数
data = numpy.random.random_integers(1,20000,30) #生成整形随机数
#正态随机数 numpy.random.normal(均值,偏离值,个数) 偏离值决定了每个数之间的差 ,当偏离值大于开始值的时候,那么会产生负数的。
data1 = numpy.random.normal(3.2,29.2,10) # 生成浮点型且是正负数的随机数
# pandas
使用pip install pandas即可
直接上代码: 下面看看pandas输出的结果, 这一行的数字第几列,第一列的数字是行数,定位一个通过第一行,第几列来定位:
print(b)
0 1 2 3
0 1 2 3 4.0
1 sdaf dsaf 18hd NaN
2 1463 None None NaN
常用方法如下:
import pandas
a=pandas.Series([1,2,3,34,]) # 等于一维数组
b=pandas.DataFrame([[1,2,3,4,],["sdaf","dsaf","18hd"],[1463]]) # 二维数组
print(b.head()) # 默认取头部前5行,可以看源码得知
print(b.head(2)) # 直接传入参数,如我写的那样
print(b.tail()) # 默认取尾部前后5行
print(b.tail(1)) # 直接传入参数,如我写的那样
下面看看pandas对数据的统计,下面就说说每一行的信息
# print(b.describe()) # 显示统计数据信息
3 # 3表示这个二维数组总共多少个元素
count 1.0 # 总数
mean 4.0 # 平均数
std NaN # 标准数
min 4.0 # 最小数
25% 4.0 # 分位数
50% 4.0 # 分位数
75% 4.0 # 分位数
max 4.0 # 最大值
转置功能:把行数转换为列数,把列数转换为行数,如下所示:
print(b.T) # 转置
0 1 2
0 1 sdaf 1463
1 2 dsaf None
2 3 18hd None
3 4 NaN NaN
# 通过pandas导入数据
pandas支持多种输入格式,我这里就简单罗列日常生活最常用的几种,对于更多的输入方式可以查看源码后者官网。
# CSV文件
csv文件导入后显示输出的话,是按照csv文件默认的行输出的,有多少列就输出多少列,比如我有五列数据,那么它就在prinit输出结果的时候,就显示五列
csv_data = pandas.read_csv('F:\Learnning\CSDN-python大数据\hexun.csv')
print(csv_data)
# excel表格
- 依赖于xlrd模块,请安装它。
- 老样子,原滋原味的输出显示excel本来的结果,只不过在每一行的开头加上了一个行数
excel_data = pandas.read_excel('F:\Learnning\CSDN-python大数据\cxla.xls')
print(excel_data)
# 读取SQL
依赖于PyMySQL,所以需要安装它。pandas把sql作为输入的时候,需要制定两个参数,第一个是sql语句,第二个是sql连接实例。
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="root",db="test")sql="select * from fortest"e=pda.read_sql(sql,conn)
# 读取HTML
- 依赖于lxml模块,请安装它。
- 对于HTTPS的网页,依赖于BeautifulSoup4,html5lib模块。
- 读取HTML只会读取HTML里的表格,也就是只读取
<table>标签包裹的内容.
html_data = pandas.read_html('F:\Learnning\CSDN-python大数据\shitman.html') # 读取本地html文件。
html_from_online = pandas.read_html('https://book.douban.com/') # 读取互联网的html文件
print(html_data)
print('html_from_online')
显示的是时候是通过python的列表展示,同时添加了行与列的标识
# 读取txt文件
输出显示的时候同时添加了行与列的标识
text_data = pandas.read_table('F:\Learnning\CSDN-python大数据\dforsay.txt')print(text_data)
# scipy
安装方法是先下载whl格式文件,然后通过pip install “包名” 安装。whl包下载地址是:http://www.lfd.uci.edu/~gohlke/pythonlibs/f9r7rmd8/scipy-0.18.1-cp35-cp35m-win_amd64.whl
# matplotlib 数据可视化分析
我们安装这个模块直接使用pip install即可。不需要提前下载whl后通过 pip install安装。
下面请看代码:
from matplotlib import pylab
import numpy
# 下面2行定义X轴,Y轴
x=[1,2,3,4,8]
y=[1,2,3,4,8]
# plot的方法是这样使用(x轴数据,y轴数据,展现形式)
pylab.plot(x,y) # 先把x,y轴的信息塞入pylab里面,再调用show方法来画图
pylab.show() # 这一步开始画图,默认是至线图
画出的图是这样的:
# 下面说说修改图的样式
# 关于图形类型,有下面几种:
- 直线图(默认)
-直线
- -- 虚线
- -. -.形式
- : 细小虚线
# 关于颜色,有下面几种:
- c-青色
- r-红色
- m-品红
- g-绿色
- b-蓝色
- y-黄色
- k-黑色
- w-白色
# 关于形状,有下面几种:
- s 方形
*星形
- p 五角形
我们还可以对图稍作修改,添加一些样式,下面修改圆点图为红色的点,代码如下:
pylab.plot(x,y,'or') # 添加O表示画散点图,r表示redpylab.show()
我们还可以画虚线图,代码如下所示:
pylab.plot(x,y,'r:')
pylab.show()
还可以给图添加上标题,x,y轴的标签,代码如下所示
pylab.plot(x,y,'pr--') #p是图形为五角星,r为红色,--表示虚线
pylab.title('for learnning') # 图形标题
pylab.xlabel('args') # x轴标签
pylab.ylabel('salary') # y轴标签
pylab.xlim(2) # 从y轴的2开始做线
pylab.show()
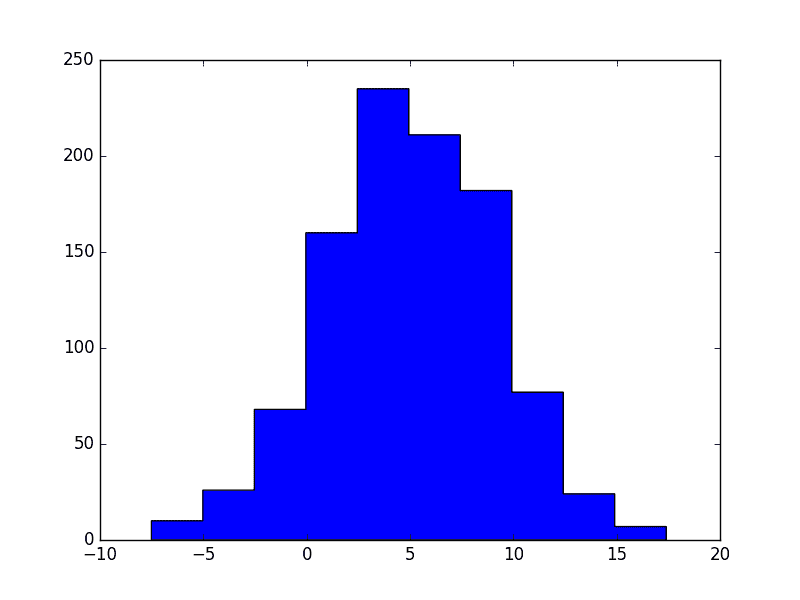
# 直方图
利用直方图能够很好的显示每一段的数据。下面使用随机数做一个直方图。
data1 = numpy.random.normal(5.0,4.0,10) # 正态随机数
pylab.hist(data1)
pylab.show()
Y轴为出现的次数,X轴为这个数的值(或者是范围)
# 还可以指定直方图类型通过histtype参数:
图形区别语言无法描述很详细,大家可以自信尝试。
- bar :is a traditional bar-type histogram. If multiple data are given the bars are aranged side by side.
- barstacked :is a bar-type histogram where multiple data are stacked on top of each other.
- . step :generates a lineplot that is by default unfilled.
- stepfilled :generates a lineplot that is by default filled.
举个例子:
sty=numpy.arange(1,30,2)
pylab.hist(data1,histtype='stepfilled')
pylab.show()
# 子图功能
什么是子图功能呢?子图就是在一个大的画板里面能够显示多张小图,每个一小图为大画板的子图。
我们知道生成一个图是使用plot功能,子图就是subplog。代码操作如下:
#subplot(行,列,当前区域)
pylab.subplot(2,2,1) # 申明一个大图里面划分成4块(即2*2),子图使用第一个区域(坐标为x=1,y=1)
pylab.subplot(2,2,2) # 申明一个大图里面划分成4块(即2*2),子图使用第二个区域(坐标为x=2,y=2)
x1=[1,4,6,9]
x2=[3,21,33,43]
pylab.plot(x1,x2) # 这个plot表示把x,y轴数据塞入前一个子图中。我们可以在每一个子图后使用plot来塞入x,y轴的数据
pylab.subplot(2,1,2) # 申明一个大图里面划分成2块(即),子图使用第二个区域(坐标为x=1,y=2)
pylab.show()
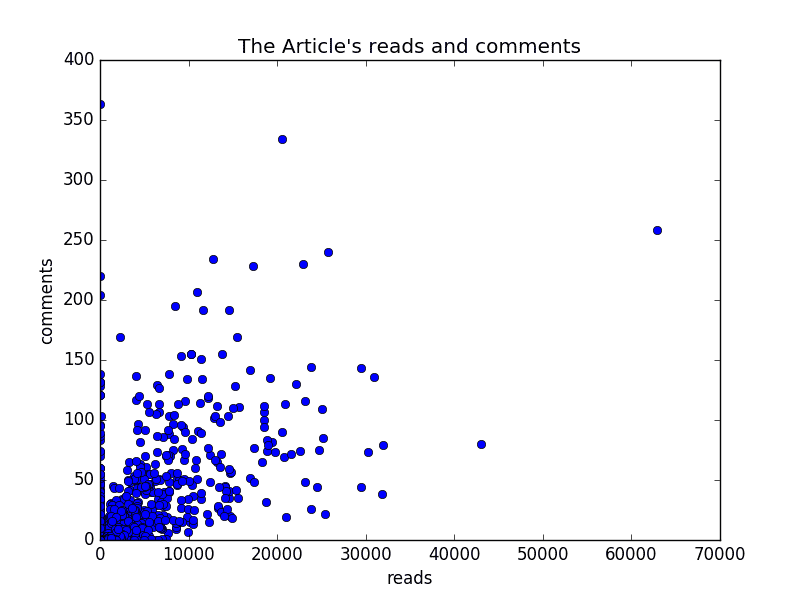
# 实践小例子
我们现在可以通过一堆数据来绘图,根据图能够很容易的发现异常。下面我们就通过一个csv文件来实践下,这个csv文件是某个网站的文章阅读数与评论数。
先说说这个csv的文件结构,第一列是序号,第二列是每篇文章的URL,第三列每篇文章的阅读数,第四列是每篇评论数。
我们的需求就是把评论数作为Y轴,阅读数作为X轴,所以我们需要获取第三列和第四列的数据。我们知道获取数据的方法是通过pandas的values方法来获取某一行的值,在对这一行的值做切片处理,获取下标为3(阅读数)和4(评论数)的值,但是,这里只是一行的值,我们需要是这个csv文件下的所有评论数和阅读数,那怎么办?聪明的你会说,我自定义2个列表,我遍历下这个csv文件,把阅读数和评论数分别添加到对应的列表里,这不就行了嘛。呵呵,其实有一个更快捷的方法,那么就是使用T转置方法,这样再通过values方法,就能直接获取这一评论数和阅读数了,此时在交给你matplotlib里的pylab方法来作图,那么就OK了。了解思路后,那么就写吧。
下面看看代码:
csv_data = pandas.read_csv('F:\Learnning\CSDN-python大数据\hexun.csv')
dt = csv_data.T # 装置下,把阅读数和评论数转为行
readers=dt.values[3]
comments = dt.values[4]
pylab.xlabel(u'reads')
pylab.ylabel(u'comments') # 打上标签
pylab.title(u"The Article's reads and comments")
pylab.plot(readers,comments,'ob')
pylab.show()
# 【----------------------------】
# python数据挖掘常用模块
- numpy模块:用于矩阵运算、随机数的生成等
- pandas模块:用于数据的读取、清洗、整理、运算、可视化等
- matplotlib模块:专用于数据可视化,当然含有统计类的seaborn模块
- statsmodels模块:用于构建统计模型,如线性回归、岭回归、逻辑回归、主成分分析等
- scipy模块:专用于统计中的各种假设检验,如卡方检验、相关系数检验、正态性检验、t检验、F检验等
- sklearn模块:专用于机器学习,包含了常规的数据挖掘算法,如决策树、森林树、提升树、贝叶斯、K近邻、SVM、GBDT、Kmeans等
# 数据分析和挖掘推荐的入门方式是?小公司如何利用数据分析和挖掘?
关于数据分析与挖掘的入门方式是先实现代码和Python语法的落地(前期也需要你了解一些统计学知识、数学知识等),这个过程需要你多阅读相关的数据和查阅社区、论坛。然后你在代码落地的过程中一定会对算法中的参数或结果产生疑问,此时再去查看统计学和数据挖掘方面的理论知识。这样就形成了问题为导向的学习方法,如果将入门顺序搞反了,可能在硬着头皮研究理论算法的过程中就打退堂鼓了。
对于小公司来说,你得清楚的知道自己的痛点是什么,这些痛点是否能够体现在数据上,公司内部的交易数据、营销数据、仓储数据等是否比较齐全。在这些数据的基础上搭建核心KPI作为每日或每周的经营健康度衡量,数据分析侧重于历史的描述,数据挖掘则侧重于未来的预测。
差异在于对数据的敏感度和对数据的个性化理解。换句话说,就是懂分析的人能够从数据中看出破绽,解决问题,甚至用数据创造价值;不懂分析的人,做不到这些,更多的是描述数据。
# 请问能稍微介绍下数据分析与数据挖掘的应用场景么?
不妨举两个典型的例子:
# 1)识别互联网行业中的“黄牛”。
移动互联网时代下,电商平台之间的竞争都特别的激烈,为了获得更多的新用户,往往会针对新用户发放一些诱人的福利,如红包券、满减券、折扣券、限时抢购优惠券等,当用户产生交易时,就能够使用这些券减免一部分交易金额。然而,某些心念不正的用户为了从中牟取利益,破坏大环境下的游戏规则。以某电商为例,数据分析人员在一次促销活动的复盘过程中,发现交易记录存在异常,于是就对这批异常交易作更深层次的分析和挖掘。最终发现这批异常交易都有两个共同特点,那就是一张银行卡对应数百个甚至上千个用户id,同时,这些id至始至终就发生一笔交易。
暗示了什么问题?这就说明用户很可能通过廉价的方式获得多个手机号,利用这些手机号去注册APP成为享受福利的多个新用户,然后利用低价优势买入这些商品,最后再以更高的价格卖出这些商品,这种用户我们一般称为“黄牛”。
# 2)完美的动态定价营销法。
打车工具的出现,改变了人们的出行习惯,也改善了乘车的便捷性,以前都是通过路边招手才能乘上出租车,现在坐在家里就可以完成一对一的打车服务。起初滴滴、快滴、优步、易到等打车平台,为了抢占市场份额,不惜一切代价,花费巨资补贴给司机端和乘客端,在一定程度上获得了用户的青睐,甚至导致用户在短途出行中都依赖上了这些打车工具。然而随着时间的推移,打车市场的格局基本定型,企业为了自身的利益和长远的发展,不再进行这种粗放式的“烧钱”运营手段。
当司机端和乘客端不再享受以前的福利待遇时,一定程度上会影响乘客端的乘车频率和司机端的接单积极性。为了弥补这方面的影响,某打车平台将利用用户的历史交易数据,为司机端和乘客端的定价进行私人订制。例如针对乘客端,通过各种广告渠道将折扣券送到用户手中,一方面可以唤醒部分沉默用户(此时的折扣力度会相对比较高),让他们再次回到应用中产生交易,另一方面继续刺激活跃用户的使用频率(此时的折扣力度会相对比较低),进而提高用户的忠诚度;针对司机端,根据司机在平台的历史数据,将其接单习惯、路线熟悉度、路线拥堵状况、距离乘客远近、天气变化、乘客乘坐距离等信息输入到逻辑模型中,可以预测出司机接单的概率大小。这里的概率一定程度上可以理解为司机接单的意愿,如果概率越高,则说明司机接单的意愿就越强,否则意愿就越弱。
当模型发现司机接单的意愿比较低时,就会发放较高的补贴给司机端,否则司机就会获得较少的补贴甚至没有补贴。如果不将数据分析与挖掘手段应用于大数据的交通领域,就无法刺激司机端和乘客端的更多交易,同时,也会浪费更多的资金,造成营成本居高不下,影响企业的发展和股东的利益。
# 总结
更多数据挖掘内容,可以参见人工智能的相关章节内容。
# 参考文章
- https://www.cnblogs.com/liaojiafa/p/6239262.html
- https://www.jianshu.com/p/e13c32b5c21f










